![[Database System] Database Logging](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbkZxXI%2FbtsyQNACZsK%2FAAAAAAAAAAAAAAAAAAAAAODr6D_zxV3kBoe7Zbmg4U4mgbcldtFs8m_cmlLv02kP%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3Dmj5HY%252BoM%252FEfiUhCf5pqbviAwemU%253D)
Failure Classification
DBMS에서 발생할 수 있는 failure의 타입은 다음과 같다.
Type1: Transaction Failure
Type2: System Failure
Type3: Storage Media Failures
Transaction Failures
트랜잭션 실패에는 크게 두 가지 유형이 존재한다.
1. Logical Erros
논리적 에러는 트랜잭션이 내부 오류 조건(무결성 제약 조건 위반)으로 인해 완료되지 않는 상황을 의미한다.
2. Internal State Erros
내부 상태 에러는 DBMS가 active transaction을 종료해야 하는 오류 조건(ex. Deadlock)으로 인해 발생하는 상황을 말한다.
예시로 들었던 Deadlock이 발생하면, DBMS는 해당 교착 상태를 해결하기 위해 하나 이상의 트랜잭션을 종료시켜야한다.
System Failures
시스템 실패는 DBMS 또는 OS와 관련된 문제로 인해 발생하는 문제를 말한다.
1. Software Failure
OS과 DBMS 구현에서 발생하는 문제를 말한다. 예를 들어, divide-by-zero exception이 있다.
2. Hardware Failure
하드웨어 실패는 DBMS가 실행 중인 컴퓨터의 하드웨어에 문제가 발생하는 경우를 말한다.
정전 또는 갑작스러운 충돌로 인해 다운되는 경우 Hardware Failure가 발생할 수 있다.
DBMS는 hardware failure이 발생해도 Non-volatile storage에 저장된 내용이 손상되지 않음을 보장해야 하는데, 이를 Fail-stop Assumption이라고 한다.
Storage Media Failure
저장 매체 실패는 주로 데이터베이스 시스템의 물리적 저장 매체에서 발생하는 문제이다.
1. Non-Repairable Hardware Failure
저장 매체에서 발생하는 심각한 하드웨어 문제를 말하며, 복구가 불가능한 수준의 실패를 말한다.
예를들어, head crash와 같은 실패는 저장 매체의 일부 혹은 전체를 파괴할 수 있다.
disk controller는 이러한 failure를 감지하기 위해 checksums을 사용한다.
Undo vs Redo
Undo는 트랜잭션이 완료되지 않거나 중단된 경우 해당 트랜잭션의 영향을 제거하거나 복구하는 프로세스이다.
Redo는 커밋된 트랜잭션의 영향을 영구적으로 만드는 프로세스로, 커밋된 트랜잭션에서 수행된 변경사항을 다시 적용하여 데이터베이스를 영구적으로 업데이트한다.
DBMS가 이러한 Undo나 Redo 기능을 지원하는 방법은 buffer pool 관리와 관련이 있다.
Buffer pool은 메모리 공간을 관리하여 데이터베이스 작업의 성능을 최적화하는 역할을 하며 Undo 및 Redo 작업은 buffer pool 내부에서 이루어지게 된다.
Buffer Pool의 작동 방식은 다음과 같다.
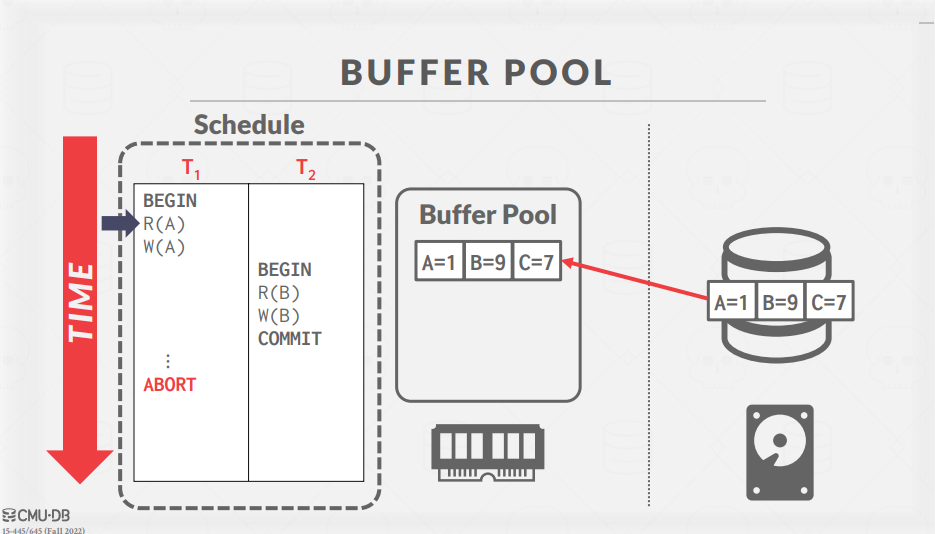
READ A 명령을 읽으면, DBMS는 disk에서 해당하는 page를 fetch하여 메모리로 가져온다.

이후 Write A 커맨드를 실행하여, 메모리에 가져온 페이지에 Write를 수행한다.

이제 T2의 Command를 수행하기 위해 page B로 context switching이 일어난다.

Write B 커맨드를 수행하여 메모리의 B값이 변경된 것을 확인할 수 있다.
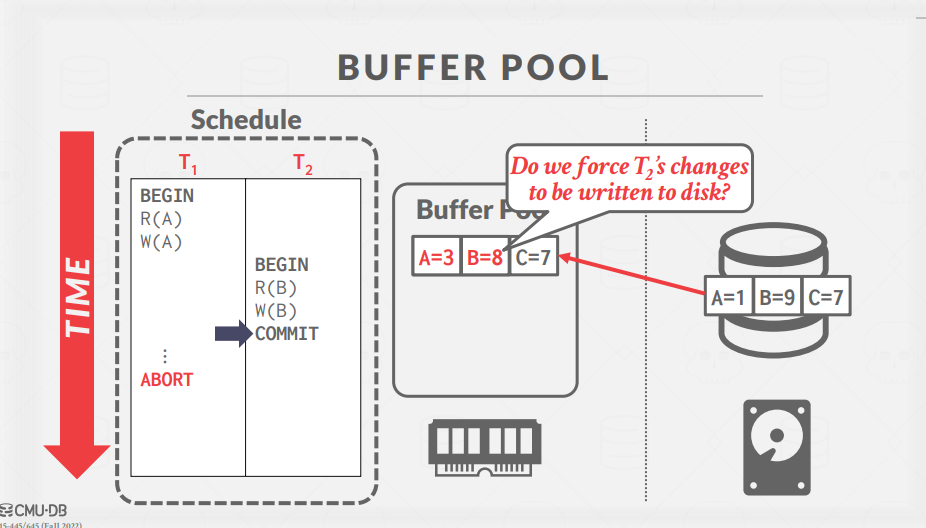
이후 COMMIT 명령을 만나 T2의 모든 동작이 디스크에 반영되어야한다.
그
러나 여기서 문제가 존재하는데, 같은 Page에 존재하는 A의 값도 변경되었지만, T1에서는 아직 COMMIT되지 않았다는 점이다.
B의 변경 값을 반영하기 위해서는 해당 Page의 정보를 모두 Disk에 반영해야하는데, 이러면 아직 COMMIT 되지 않은 A의 변경 값까지 DISK에 반영되는 문제점이 존재한다.
이러한 문제를 해결하기 위해 언제 dirty page를 disk에 적을 것인지, transaction이 commit 되었다고 할 수 있는 조건사항은 무엇인지를 다루는 것이 매우 중요한데, 이를 다루기 위한 두 가지의 버퍼 정책이 존재한다.
Steal Policy
Steal Policy는 DBMS가 아직 commit 되지 않은 transaction을 가장 최근에 commit된, non-volatile에 있는 값을 overwrite하는 것을 허용할지에 대한 것을 결정한다.
STEAL의 경우 이를 허용하고, NO-STEAL의 경우 이를 허용하지 않는다.
Force Policy
트랜잭션 완료 후, 데이터를 바로 디스크에 반영할 것인가에 대한 정책이다.
FORCE의 경우 이를 바로 반영하고, NO-FORCE의 경우 바로 반영하지 않는다.
NO-STEAL + FORCE 예시
NO-STEAL과 FORCE 정책이 적용된 예시를 살펴보면 아래와 같이 동작한다.

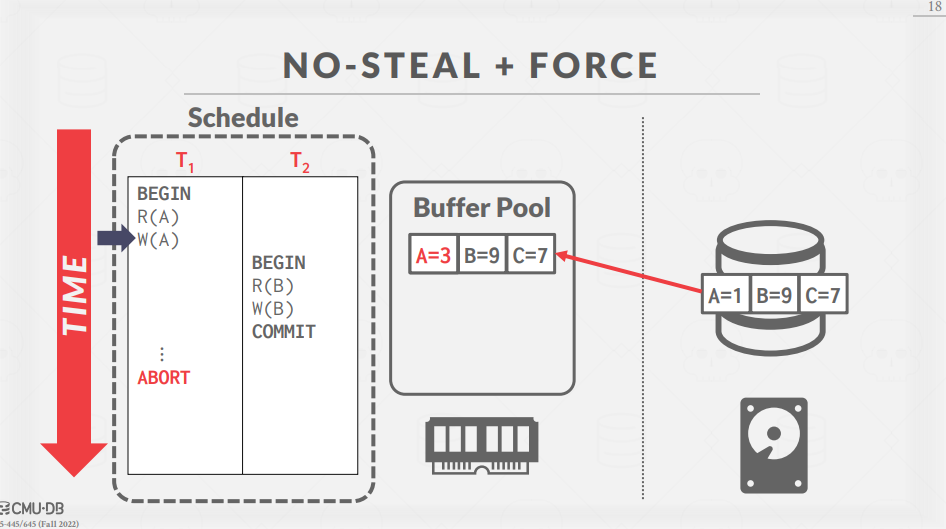
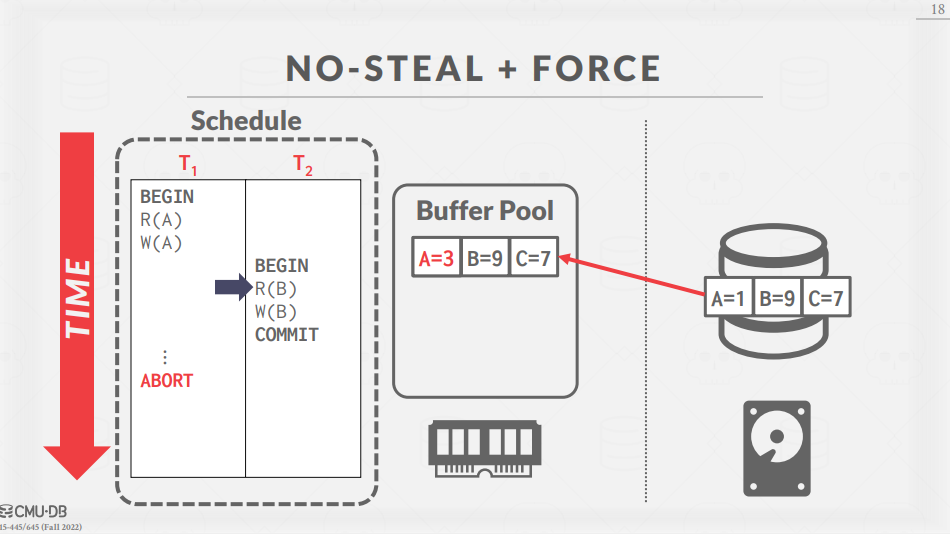
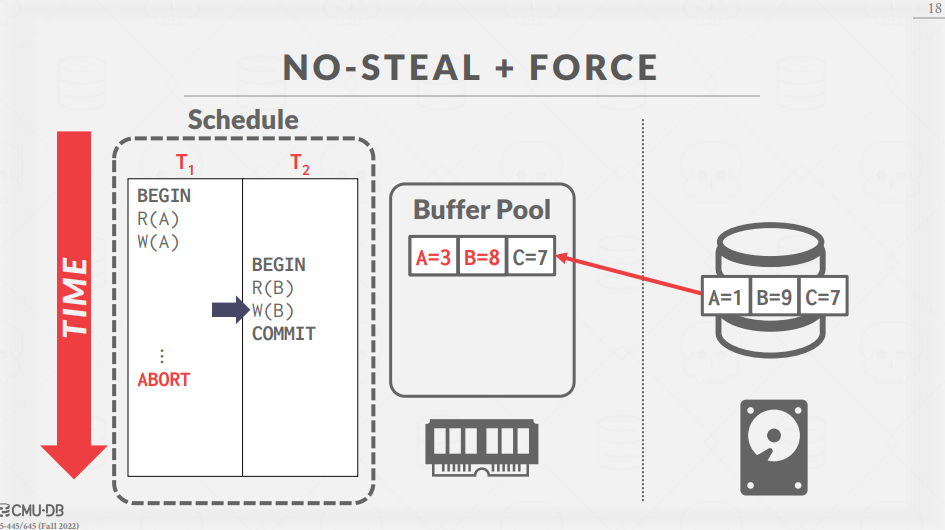
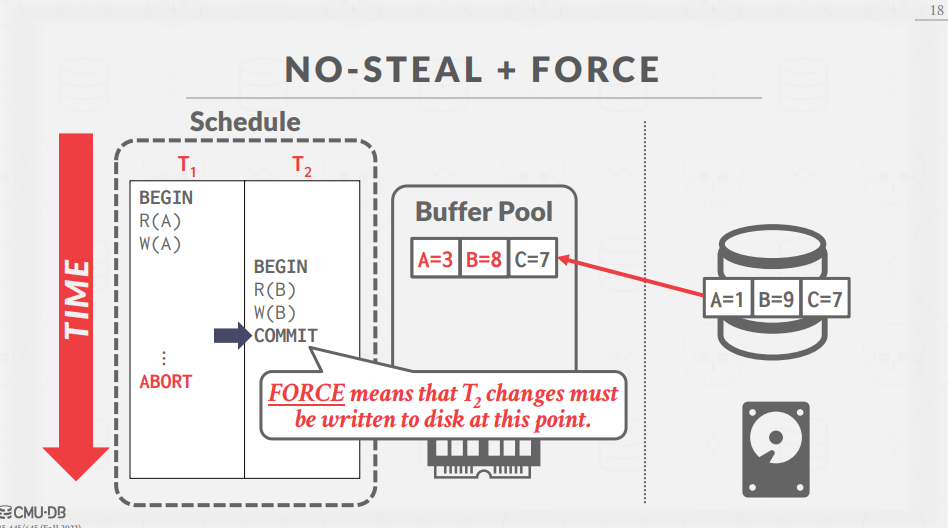
여기서, FORCE 정책이 적용되었기 때문에, COMMIT이 수행되면 즉시 Buffer Pool에 있는 변경 사항이 disk에 반영되어야 한다.
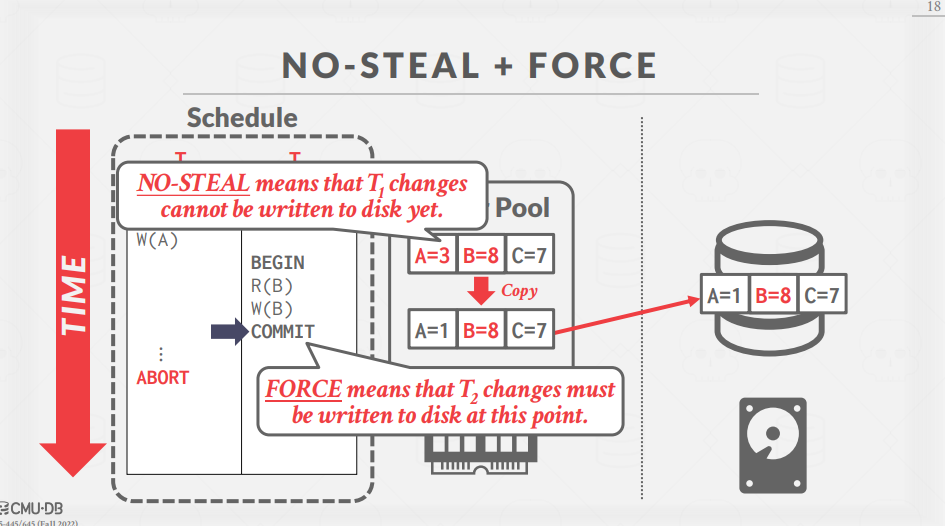
다만, NO-STEAL 정책이 적용되어있기때문에 COMMIT되지 않은 A의 변경사항이 Disk에 반영되어서는 안 된다.
따라서 위와 같이 Page를 Copy한 후, B의 변경사항만을 반영한 후 disk에 re-write한다.

이제는 T1에 ABORT된 경우에도, 쉽게 원래 상태로 돌아갈 수 있다.
왜냐하면 disk에 T1을 원래 상태로 돌릴 수 있는 정보가 남아있기 때문이다.
NO-STEAL + FORCE 정책의 경우 가장 구현하기 쉬운 방법에 해당한다.
변경 사항이 disk에 적히지 않기 때문에 aborted transaction에 대한 undo 과정에 간소화되며,
모든 commited transaction이 disk에 반영되어 있기 때문에 redo 과정이 필요 없어진다는 장점이 있다.
다만 이전 예시에서는 physical memory에서 한계가 발생할 수 있다. 메모리 내 버퍼 공간이 한정되어 있으므로 많은 양의 쓰기 집합(write-set)을 지원하기 힘들다. 따라서 성능 면에서 단점이 존재한다고 할 수 있다.
Shadow Paging
Shadow Paging은 데이터베이스의 일관성 및 내구성을 보장하기 위한 방법으로, 데이터베이스 전체를 복사하는 대신 페이지 복사를 사용하여 Master, Shadow 두 가지 버전을 생성한다.
Master 페이지의 경우 이미 커밋된 트랜잭션에 의해 발생한 변경 사항만을 포함하며
Shadow 페이지의 경우 아직 커밋되지 않은 트랜잭션에서 발생한 변경 사항을 포함한다.
일반적으로 `Root page`는 변경사항을 가리키는 포인터를 가지고 있다. 트랜잭션이 커밋되면 루트 페이지를 갱신하여 shadow 페이지로 포인터가 변경되며, Master 페이지가 더 이상 사용되지 않게된다.
따라서 Master Page와 Shadow Page 간의 역할이 바꾸고, 새로운 변경사항이 Master Page에 사용되기 시작한다.
동작 예시는 아래와 같다.
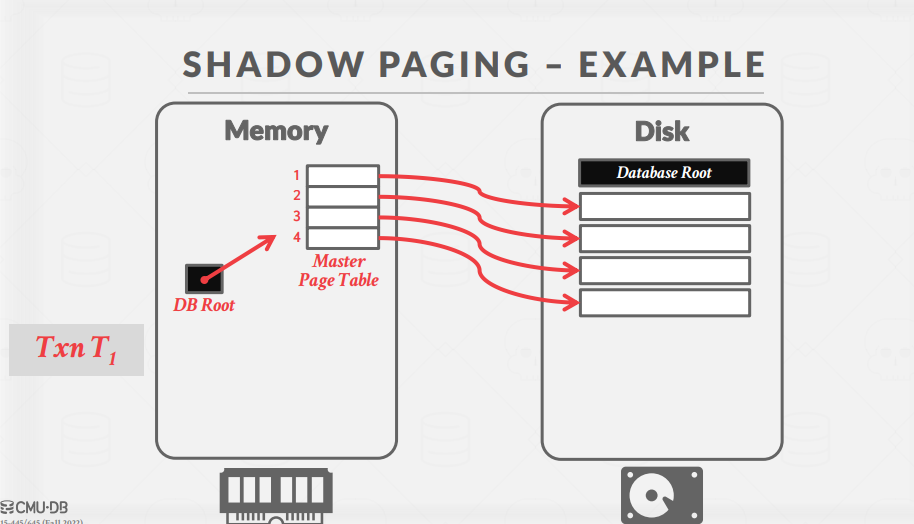

초기에는 Shadow Page와 Master Page가 동일한 Page에 대한 참조를 가지고 있다.

그러나 Transaction이 수행되어 Shadow Page Table의 entry 값의 변화가 발생하면, 변화가 발생한 Page를 Disk에 반영하고 이에 대한 참조를 가지게 된다.
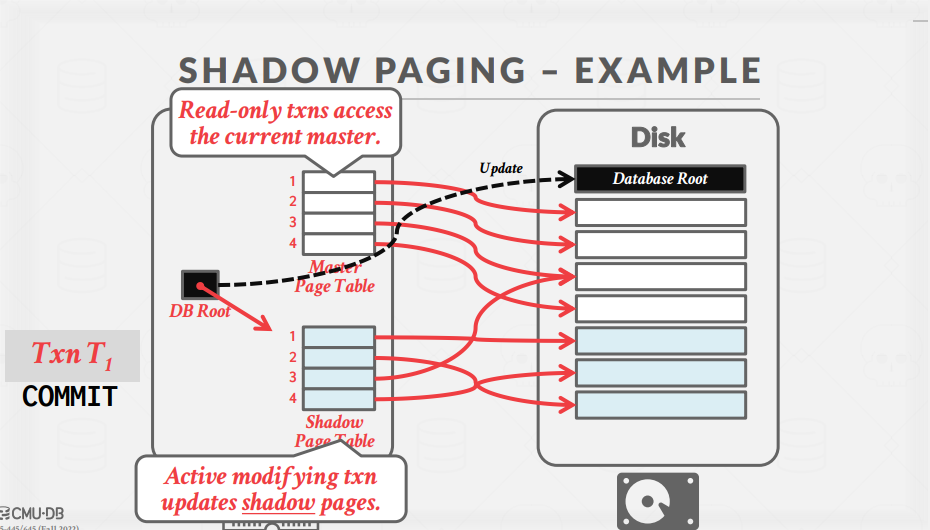
이후 COMMIT이 실행되면, DB Root를 업데이트하며 Shadow Page Table을 참조하게 하고, Master Page Table을 제거한 후 Shadow Page Table을 Master Page Table로 업데이트한다.
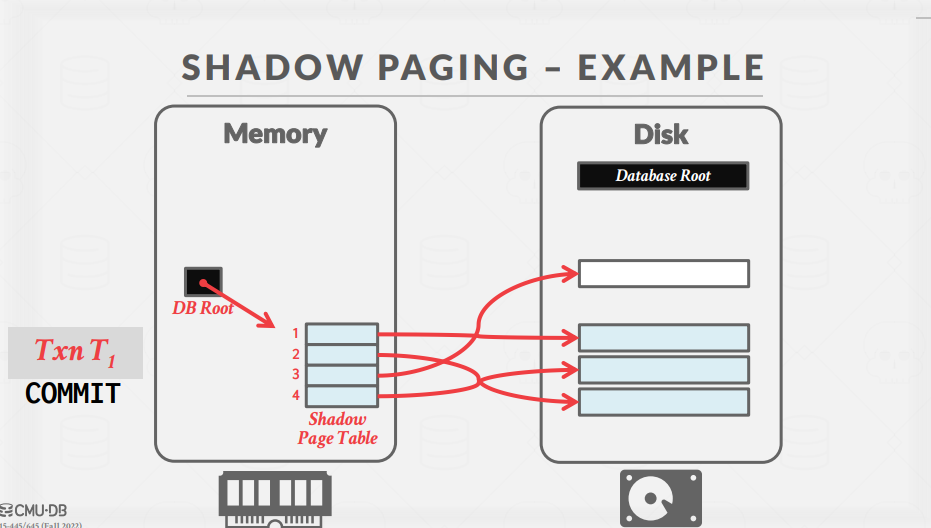
Shadow Paging 방식을 사용하면 Undo 작업이 매우 간단해진다. 단순히 Shadow Page를 제거하고 원래 상태를 유지하면 되기 때문이다.
Redo의 경우에는 이미 Shadow Page의 모든 변경 사항이 DISK에 반영되었기 때문에 추가적으로 필요한 행위는 존재하지 않는다.
Shadow Paging의 단점은 page table의 복사 비용이 너무 크다는 것이다.
이는 B+ tree와 같은 page table 구조를 사용하고, updated leaf nodes에 대한 path만을 저장하는 방식으로 극복할 수 있다.
다만 commit 오버헤드도 매우 크다는 단점이 있다. page, page table, root에 대한 모든 변경사항을 Flush해야 하기 때문이다. 또한 이로 인해 disk 공간이 fragmented 될 수 있는데, 이는 순차 접근에 대한 효율성을 크게 떨어뜨린다.
추가적으로 Master Page가 삭제될 때 Garbage Collection을 필요로 한다는 단점이 있다.
Write Ahead Log(WAL)
데이터베이스는 데이터 파일과 별도로 로그 파일을 유지한다.
이 로그 파일은 트랜잭션이 수행하는 변경 사항을 기록하는 역할을 한다.
로그 파일은 안전한 저장장치에 유지된다는 가정을 기반으로 동작하며, 로그 파일은 필요한 undo나 redo 작업을 수행하기 위해 충분한 정보를 가지고 있어야 한다.
Write-Ahead Log 원칙에 따르면, 데이터베이스 시스템은 object를 disk로 flush 하기 전에, log file records를 먼저 disk에 반영해야 한다.
WAL 프로토콜의 구체적인 특성은 아래와 같다.
1. Log Staging
모든 트랜잭션의 로그 레코드는 volatile storage에 저장된다. 이는 일반적으로 버퍼 풀로 구성되며, 변경 사항은 메모리에 저장된다.
2. Log Records
트랜잭션이 데이터베이스 페이지를 업데이트하면 해당 변경 사항에 대한 로그 레코드가 생성된다.
이 로그 레코드에는 변경된 페이지의 주소, 변경 내용, 트랜잭션 ID 등의 정보가 포함된다.
3. Write to Non-Volatile Storage
모든 트랜잭션 레코드는 해당 트랜잭션이 변경한 페이지에 대한 변경 사항이 실제로 디스크에 반영되기 전에 non-volatile storage에 안전하게 기록되어야 한다.
WAL Protocol에서는 log에 <BEGIN> record를 작성하는데, 이는 각 transaction의 시작점을 표시하는 역할을 한다.
transaction 완료 시, DBMS는 log에 <COMMIT> record를 작성하고, 모든 log recrods를 flush 한다.
각 log entry에는 single object에 대한 정보가 담겨있는데,
Transaction Id, Object Id, Before Value(UNDO를 위한 정보), After Value(REDO를 위한 정보) 등이 존재한다.
WAL의 동작 방식은 다음과 같다.

Transaction이 시작되면, WAL BUffer에 <BEGIN> record가 기록된다.
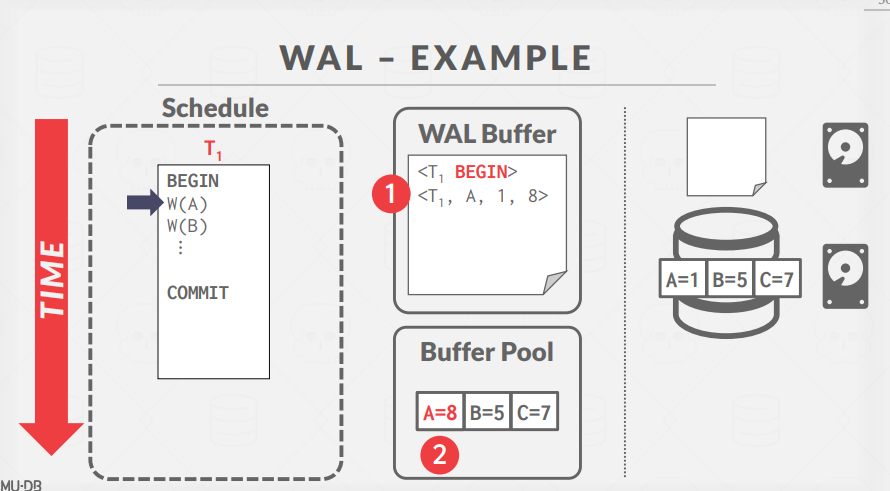
이후 Write A 동작에 의해 Buffer Pool에 있는 A의 값이 변경되고, Buffer에 Transaction ID, Object 정보, 이전 값과 이후 값이 기록된다.
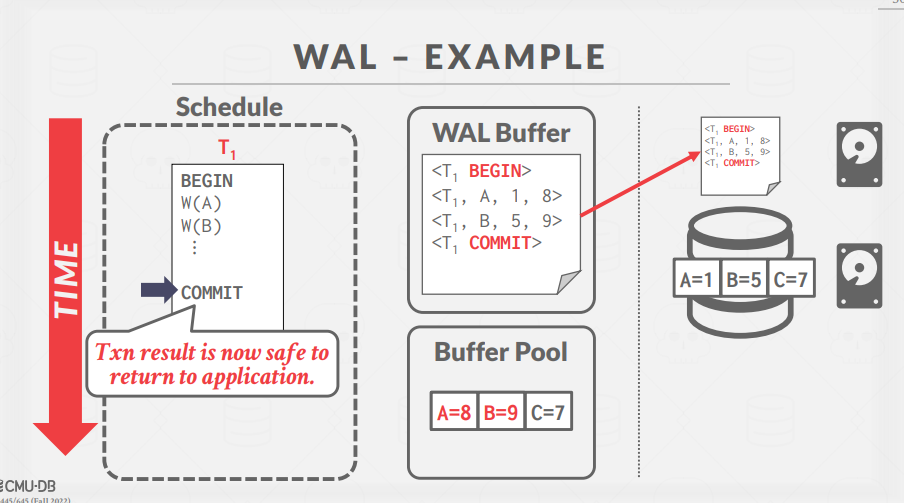
이후 COMMIT 동작을 수행하면, WAL Buffer에 <COMMIT> record가 기록된 후, disk로 flush 된다.
다만 이렇게 commit 마다 log buffer를 디스크로 flush 하는 것은 bottleneck으로 작용하여 효율성에 큰 영향을 미칠 수 있다.
DBMS는 이를 해결하기 위해 group commit을 사용할 수 있다.

Group commit 사용시에는 위와 같이, log buffer가 모두 찬 경우에 디스크로 Flush 한다.
Checkpoint
WAL의 경우 영원히 grow할 수 있는데, crash 발생 시 DBMS는 반드시 모든 log를 replay 해야하며, 이는 매우 긴 시간을 소요하게 된다.
따라서 DBMS는 주기적으로 checkpoint를 설정하고, 모든 buffer를 disk로 flush한다.
Checkpoint 동작 방식은 아래와 같다.
1. 모든 쿼리를 중단한다.
2. WAL records를 disk로 flush한다.
3. buffer pool의 modified page를 disk로 flush한다.
4. WAL에 <CHECKPOINT> record를 작성하고 flush 한다.
5. 쿼리를 재개한다.
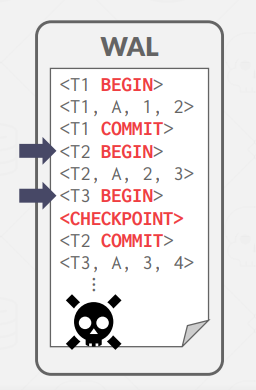
Checkpoint 이전의 commit 들은 모두 disk에 반영된 상태이므로 크래쉬가 발생해도 무시해도 된다.
크래쉬 발생 시 문제가 되는 것은 체크포인트 이후인, 위 예시에서는 T2와 T3이다.
T2의 경우 Crash 이전에 Commit이 이루어졌으므로 Redo를, T3의 경우는 Undo를 진행한다.
Buffer Pool Policies
일반적으로 DBMS는 NO-FORCE + STEAL 정책을 사용한다.

'DB' 카테고리의 다른 글
| [Database System] Recovery Algorithm (2) | 2023.10.26 |
|---|---|
| [Database System] Join Algorithm (0) | 2023.10.15 |
| [Database System] B+ Tree Index (0) | 2023.10.12 |
| [Database System] Hash Table (0) | 2023.10.09 |
| [Database System] Database Storage2 (0) | 2023.10.07 |