![[Database System] Database Storage2](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FljjdL%2FbtsxqscRg08%2FAAAAAAAAAAAAAAAAAAAAALcSlocQSi2gvrznBTvYwwDAVdc9AV_3zUAj5DSLi4bQ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3D7qqF2Sr1bsb2%252BIa%252FujOrFux6W9I%253D)
본 포스팅은 CMU의 2022 fall database system 강의 노트를 바탕으로 작성되었습니다.
What are some potential problems with the slotted page design?
앞서 살펴봤던 Slotted Paged의 경우 다음과 같은 문제점이 존재할 수 있다.
1. Fragmentation
Page는 데이터 로드의 최소 단위이므로, unusable space나 empty slots가 존재하게 될 수 있다.
2. Useless DIsk I/O
DBMS는 단 하나의 tuple을 Update 하기 위해 전체 page를 fetch 해야한다.
3. Random Disk I/O
multiple tuple을 업데이트 하는 상황에서, 각 tuple이 모두 다른 page에 존재한다면 성능에 매우 치명적인 영향을 미친다.
Log-Structured Storage
위와 같은 문제점을 보완하기 위해 tuples를 page에 저장하는 대신 DBMS는 tuple에 대한 변화를 저장한 log를 관리할 수 있는데, 이를 `Log-Structured Storage`라고 한다.
각각의 log entry는 tuple의 PUT/DELETE operation을 저장한다.
DBMS는 새로운 로그 entry를 in-memory buffer에 저장하며 변화를 sequential하게 disk에 저장한다.

특정 id를 가진 tuple에 대한 read를 진행할때, DBMS는 해당 i에 해당하는 가장 최근의 log record를 찾는다.

만약 별 다른 처리가 없이 이 과정을 수행하기 위해서는 log들을 순차적으로 확인하며 가장 최근의 log를 탐색하는데 시간을 소요해야 한다.
이 Cost를 줄이기 위해 DBMS는 index를 사용하는데, index는 tuple id와 newest log record를 mapping 해주는 역할을 한다.
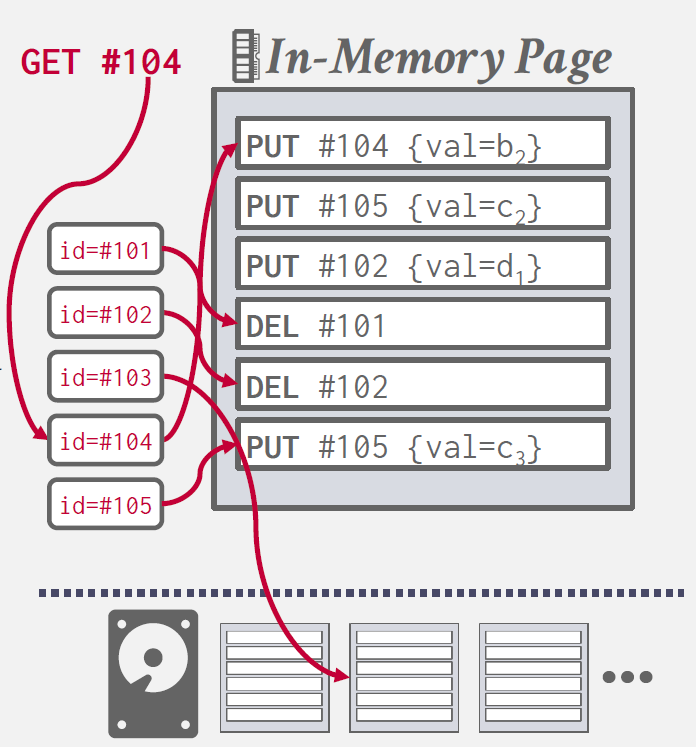
위 그림과 같이, 만약 record가 in-memory라면 해당 파트를 read하고, disk page에 존재한다면 retrieve한다.
Log-Structured Compaction
DBMS는 모든 older log entries를 저장해둘 필요는 없다.
따라서 메모리 공간을 효율적으로 사용하기 위한 compaction을 진행한다.

이러한 compaction은 주기적으로 수행된다.
Page가 compacted 되고나면 DBMS는 더 이상 page에 records의 시간 순서를 저장할 필요가 없어진다.
왜냐하면 각 tuple id는 page에서 최대 1번 등장하는 것이 보장되기 때문이다.
따라서 DBMS는 page의 tuple들을 id 순서대로 정렬하는데, 이는 미래 look-ups의 효율성을 올려준다.
순서대로 정렬되어 있는 경우 Binary search 등 효율적인 탐색 알고리즘을 사용하기 유리하기 때문이다.
이를 `Sorted String Tables(SSTables)`라고 하며, search time을 줄이기 위해 indexes, filters를 header에 가지고 있다

Log-Structed Compaction은 크게 두 가지 방법으로 이루어지며, Universal Compaction과 Level Compaction이 있다.

간단하게 Universla Compaction은 sorted log file의 크기에 관계 없이 compaction을 진행하는 것이고, level compaction은 같은 크기 끼리만 진행하는 것을 말한다.
Discussion
하지만 Log-Structured Storage에도 단점이 존재한다.
1. Write amplificaiton
메모리에 있던 records들을 disk에 저장한 후, compaction을 진행해야 하는 경우 disk에서 memory로 해당 page들을 다시 load해야한다. 추가로 compaction 직후 메모리로 로드했던 page들을 다시 disk로 이동시켜야한다.
이러한 과정을 Write amplification이라고 한다.
2. Compaction is Expensive
Observation
지금까지 살펴본 heap file이나 log-structured 방식은 모두 각 tuple을 검색하는데 index에 매우 크게 의존한다.
index 없이는 원하는 tuple을 찾기 위해 선형탐색을 해야하는 경우가 많기 때문이다.
그러나 만약 DBMS가 index를 이용해 tuple을 자동으로 sorted 된 상태로 유지할 수 있다면? 더 좋은 성능을 보일 것이라 기대해볼 수 있다.
이러한 방식을 구현한 것이 `Index-Organized Storage`이다.
Index-Organized Storage
Index-Organized Storage에서 DBMS는 table의 tuple을 index data structure의 value로 저장한다.

위와 같이 tuple들은 page에 key를 기반으로 저장되어 있다.
이러한 방식은 SQLite, MySQL, ORACLE, Microsoft SQL Server등 다양한 DBMS에서 채택하고 있는 방식이다.
Tuple Storage
Tuple은 본질적으로 sequence of bytes이다.
Sequence of byte를 attribute type이나 value로 해석하는 과정은 DBMS의 역할에 해당한다.
DBMS의 catalogs는 tuple의 layout을 알아내기 위한 table의 schema information을 가지고 있다.
Data Layout


id는 32bit, cdate는 64 비트의 공간을 차지한다.
CPU가 64bit-word, 즉 64bit단위로 데이터에 접근하는 경우 위와 같은 배치는 에러로 이어질 수 있다.
이를 방지하기 위해 `padding`을 진행할 수 있다.
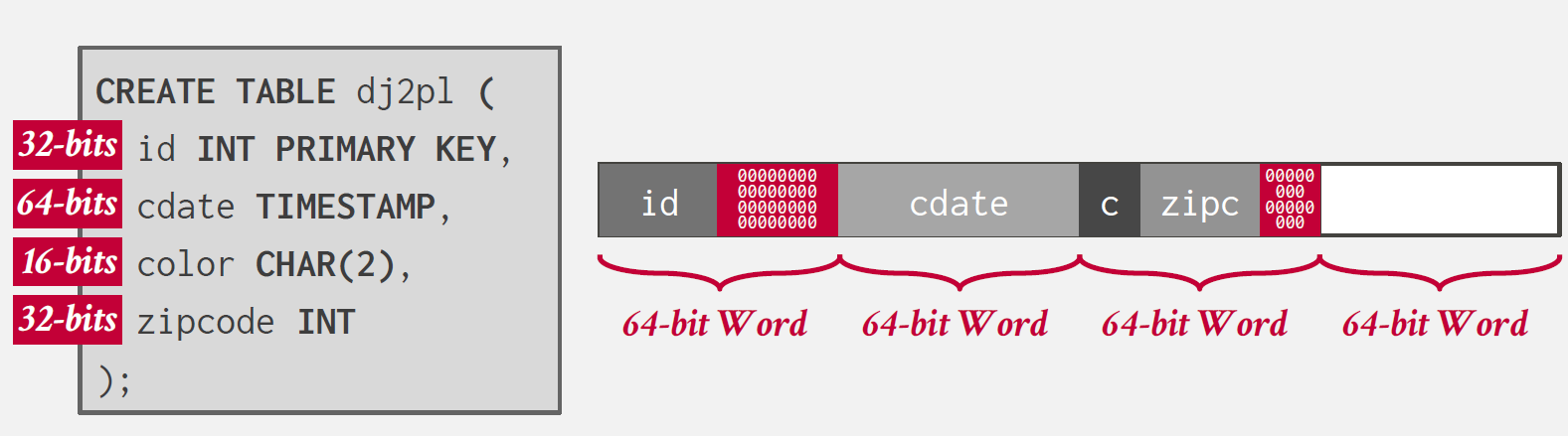
위 그림을 보면, 각 데이터들이 64bit 단위로 존재할 수 있도록 0값을 이용해 padding을 진행한 것을 확인할 수 있다.
다만 단순히 padding을 진행할 경우 저장해야 하는 실제 데이터에 비해 많은 메모리를 낭비하게 될 수 있는데, 이는 `Reordering`으로 보완할 수 있다.
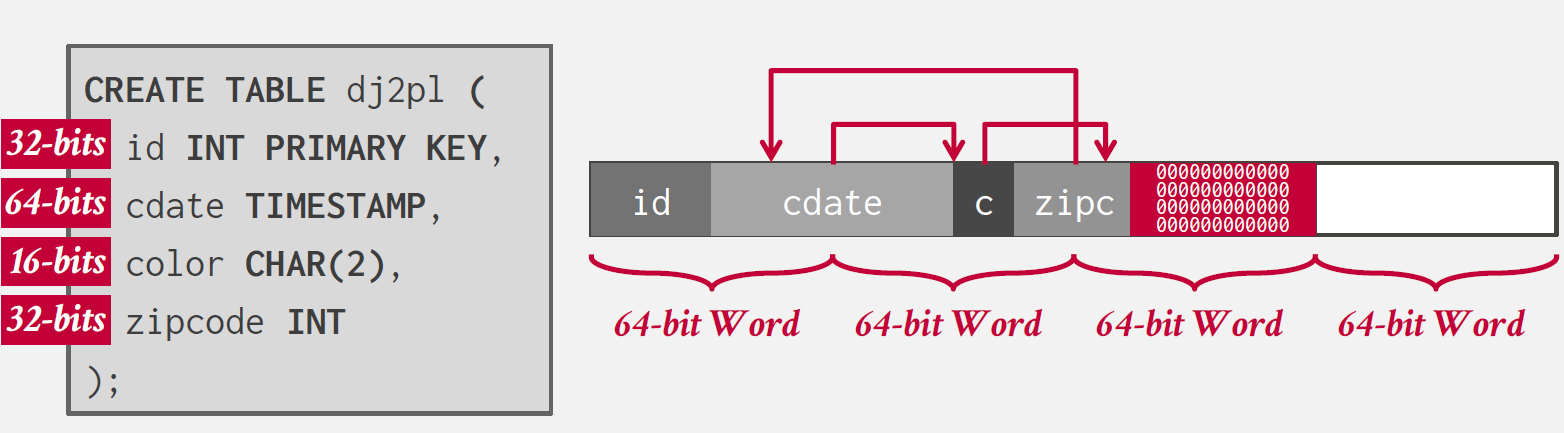
위와 같이 Reordering을 사용하면, padding으로 인해 발생하는 메모리 낭비를 줄일 수 있다.
Variable Precision Numbers
Variable Precision Numbers란 Inexact한, native C/C++ types를 사용하는 variable-precision numeric type을 말한다.
IEEE-754에 specified된 조건에 따라 저장되며 FLOAT, REAL/DOUBLE type이 그 예시이다.
이러한 type은 일반적으로 fixed precision numbers에 비해 빠른데, CPU ISA's(Xeon, Arm)등이 이를 support하는 instructions와 registers를 지원하기 때문이다.
하지만 최대 단점은, 정확한 값을 보장하지 않는다는 것이다.

Fixed Precision Numbers
Variable Precision Numbers를 사용할 때 rounding error가 있어서는 안되는 경우 Fixed Precision Numbers를 채택한다.
NUMERIC, DECIMAL이 fixed precision numbers의 예시이다.
정확한 값을 얻을 수 있다는 장점이 있지만 추가적인 meta-data와 함께 저장되어야 하기 때문에 메모리 공간의 Cost가 증가한다는 단점이 있다.
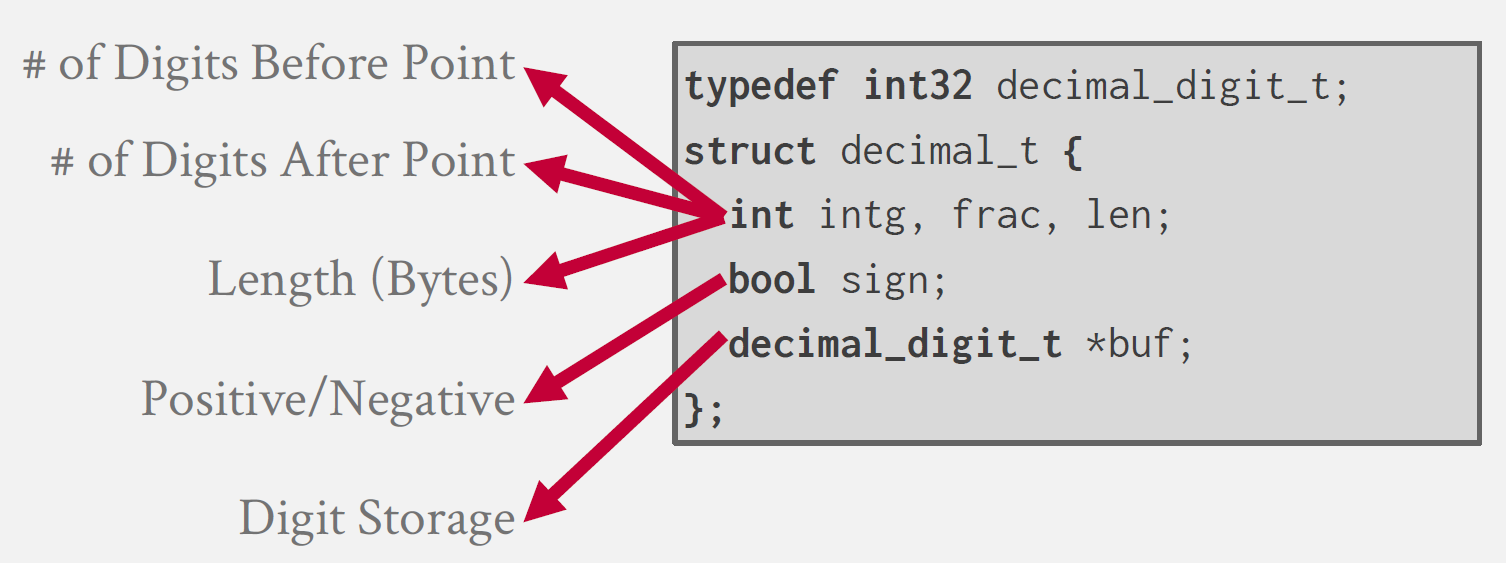
위 그림은 MySQL에서 Fixed Precision Numbers에 해당하는 DECIMAL을 저장하는 방식이다.
구조체로 선언되며, 각 변수들의 정보들을 통해 정확한 값을 도출해낸다.
Large Values
대부분의 DBMS는 single page의 사이즈를 넘는 tuple의 저장을 허용하지 않는다.
이렇게 큰 값을 저장하기 위해 DBMS는 별도의 overflow storage pages를 사용한다.

MySQL의 경우 page크기의 절반이 넘어가면 overflow page를 사용하여 데이터를 저장한다.
'DB' 카테고리의 다른 글
| [Database System] B+ Tree Index (0) | 2023.10.12 |
|---|---|
| [Database System] Hash Table (0) | 2023.10.09 |
| [Database System] Database Storage (0) | 2023.10.05 |
| [Database System] Normalization (0) | 2023.10.05 |
| [Database System] SQL과 NOSQL (0) | 2023.10.02 |