![[Database System] Database Storage](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FxSF4o%2Fbtsw8j72yte%2FAAAAAAAAAAAAAAAAAAAAAJ_VCxdJnaKiPN1VYEz5N84aWTIdK2H2aObf10ufcmmW%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D%252F1yBONQ3q1ugMqEHWVhcAfegI1M%253D)
본 포스팅은 CMU의 2022 fall database system 강의 노트를 바탕으로 작성되었습니다.
Disk-Based Architecture
DBMS은 database의 primary storage가 non-volatile disk, 즉 비휘발성 디스크에 존재한다고 가정한다.
그리고 DBMS는 이러한 비휘발성 저장공간과 휘발성 저장공간 사이에서 데이터의 움직임을 제어하는 역할을 한다.
Storage Hierarchy
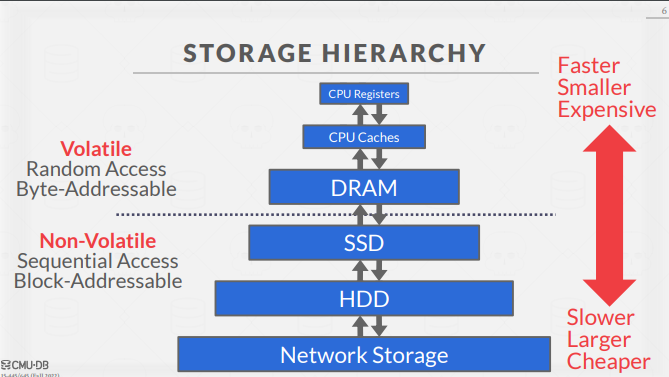
위 그림은 저장 장치 간의 hierarchy를 표현한 것으로, 위에 존재하는 저장 장치일수록 접근 속도가 빠르지만 가격이 비싸며 아래에 존재할 수록 접근 속도가 느리지만 가격이 싸다는 특징이 있다.
경제적인 측면, 그리고 데이터의 휘발성 측면에서 필연적으로 위와 같이 계층적으로 저장장치를 사용할 수 밖에 없고, 이러한 계층 관계 내에서 효율적으로 데이터가 이동하도록 관리하는 것이 DBMS의 역할이다.
Sequential VS Random Access
non-volatile 에 대한 Random access는 거의 대부분 sequential한 access보다 느리다.
그 이유는 데이터 접근 방식에 있다.
만약 우리가 HDD에서 데이터를 읽어야 하는경우, 데이터가 저장되어 있는 디스크의 측정 위치에 헤드가 위치해야 한다.
우리가 sequential한 접근을 진행하는 경우, 헤드가 이동한 후 순서대로 데이터를 읽으면 되기 때문에 헤드가 새로운 위치를 찾는 과정을 생략할 수 있다.
반면, Random Access를 진행할 경우 헤드가 계속해서 access 대상이 되는 데이터의 위치를 찾아야하며, 헤드가 해당 위치로 이동해야 한다. 이는 추가적인 Cost로 작용하기 때문에 성능 측면에서 부정적인 영향을 미치게 된다.
DBMS는 이를 고려하여 randome page에 대한 write 작업을 최소화 하고 contiguous blocks에 담길 수 있도록 알고리즘을 사용한다.
여러 페이지를 한 번에 할당하는 것을 Extent 할당이라고 하는데, 이러한 할당 방식은 Sequential access를 최적화하고 Random access를 줄이기 위한 방법 중 하나이다.
System Design Goals
DMBS를 설계할 때의 목표는 크게 세 가지로, 아래와 같다.
1. DBMS는 database를 관리하여 실제로 가능한 메모리 공간보다 더 많은 용량의 database를 관리할 수 있도록 한다.
2. disk에 발생하는 read/write는 매우 높은 cost를 요구하므로, large stalls나 performance degradation을 피하기 위해 신중한 관리를 진행한다.
3. disk에 발생하는 random access는 매우 높은 cost를 요구하므로, DBMS는 최대한 sequential access가 발생하도록 한다.
Why Not Use The OS?
DBMS는 memroy mapping을 통해 program의 address space에 file의 내용을 저장할 수 있다.
OS는 memory에서 파일을 넣고 제거하는 기능을 담당하기 때문에, DBMS는 이러한 memory mapping 작업에 대해 고려하지 않고 동작을 수행할 수 있다.

다만 OS에 의한 Memory Mapped I/O의 경우 몇 가지 문제점이 존재한다.
1. Transaction Safety
OS는 메모리 공간 관리를 위해 Mapping 되어 있던 페이지를 언제든지 디스크로 Flush 할 수 있는데, 이는 DBMS에서 진행중인 트랜잭션에 영향을 미칠 수 있다.
예를 들면, 트랜잭션이 아직 커밋되지 않은 변경 내용이 메모리에 남아 있는 경우, OS가 이를 디스크로 Flush 하면 데이터 무결성 관련 문제가 발생할 수 있다.
2. I/O Stall
FIle의 Memory load가 전적으로 OS에 의해 이루어지기 떄문에 DBMS는 어떤 페이지가 메모리에 로드되어 있는지 알지 못한다.
따라서 Page Fault가 발생하여 OS가 page를 load 하는 과정에서 DBMS가 이미 load된 page에 대한 작업을 수행할 수 있는 상황에서도 DBMS는 OS의 page fault 작업이 완료될 때 까지 대기해야한다.
3. Error Handling
Memory Mapped I/O 를 통해 file에 접근 시 DBMS는 이에 대한 예외처리를 진행해야 한다.
예를 들어, 잘못된 메모리 주소에 액세스하면 SIGBUS와 같은 예외가 발생하는데 이에 대한 예외 처리를 DBMS에서 따로 수행해주어야 하기 때문에 에러 처리가 복잡해진다.
4. Performance Issues
OS를 통한 Memory Mapped I/O 사용 시 페이지 관리에 대한 동시성 문제가 발생할 수 있다.
OS에서는 매핑된 페이지를 관리하기 위해 페이지 테이블, 페이지 폴트 처리 루틴등의 정보를 담은 데이터 구조를 가지고 있는데, 동시에 많은 Thread가 페이지를 액세스하면 이러한 데이터 구조에 대한 동기화가 필요하고, 이에 따른 성능 저하가 발생할 수 있다.
또한 Memory-Mapped page에 대한 변경 사항이 발생할 경우 TLB cache를 계속해서 업데이트해야 하는데 빈번한 TLB shootdown이 발생할 경우 CPU 오버헤드를 초래하여 성능을 저하시키게 된다.
이러한 문제를 해결하기 위해 몇 가지 Solution이 존재하는데 대표적으로 `madvise`, `mlock`, `msync` 등이 있다.
1. madvise
OS 에게 특정 page를 얼마나 read 할 것인지 미리 알린다.
2. mlock
OS가 특정 memory ranges를 paged out 하지 못하도록 한다.
3. msync
OS가 특정 memory ranges를 disk로 flush 하지 못하도록 한다.
File Storage
DBMS는 database를 하나, 혹은 그 이상의 파일로 disk에 저장한다.
OS의 경우 이 file의 contents에 대해 아무것도 알지 못하며, DBMS 만의 format으로 저장되게 된다.
Storage Manager
Storage Manager는 Database의 file을 관리하는 역할을 하며, read와 write를 schedule하며 page의 spatial locality와 temporal locality를 향상시킨다.
File을 일종의 colleciton of page로 관리하며, 페이지에 읽히거나 쓰이는 데이터를 추적하고 available space 공간을 추적한다.
Database Pages
Page는 fixed-size block of data에 해당한다.
Page는 tuple, meta-data, indexs, log records등 다양한 데이터를 포함할 수 있다.
각 Page는 구별을 위한 Unique Identifier를 가지며 DBMS는 Indirection layer를 사용하여 page ID를 물리적인 위치로 매핑한다.
Page Storage Architecture
DBMS마다 file의 page를 관리하는 방식이 다른데, 대표적으로
`Heap File Organization`, `Tree File Organizaiton`, `Sequential / Sorted File Organization`, `Hashing File Organization`등이 있다.
Heap File
Heap File이란 unordered collection of pages를 말한다.
Heap File은 여러 페이지로 구성되며, 각 페이지에는 tuple들이 저장되어 있다.
Heap File 방식의 장점은 데이터 추가에 있다.
tuple 들에 순서가 정해져 있지 않기 때문에 단순히 맨 뒤에 추가해주는 방식으로 데이터를 삽입해줄 수 있다.
하지만 Heap File은 데이터를 무작위로 저장하기 때문에 특정 데이터를 검색하려면 모든 Page를 스캔해야 한다.
따라서 데이터 검색 작업이 비효율적이다.
또한 데이터가 무작위로 저장되어 있기 때문에 Sequential Access 작업에 적합하지 않다는 단점이 있다.
이 문제를 해결하기 위해 추가적인 Index 구조를 도입해야 하는데, 이 구조 자체가 메모리와 성능에 있어 Overhead로 작용하게 된다.
Page Layout
Page Header
각 page들은 page 내용에 대한 Metadata를 header에 포함하고 있다.
이러한 Metadata에는 Page Size, Checksum, DBMS Version, Transaction Visibility 등이 존재한다.

Tuple Storage
Page에 Tuple을 저장할 때, 어떻게 저장 공간을 관리할지는 매우 중요한 문제이다.
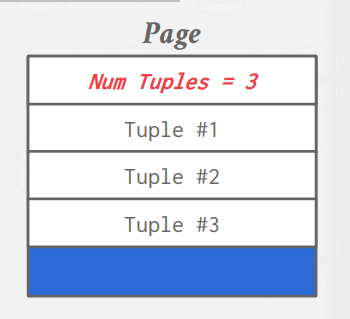
위와 같이 Page에 Tuple이 저장되어 있다고 하자.
단순히 Tuple 숫자를 저장하고, 다음 Tuple의 삽입을 Tuple 숫자에 의존해서 하는 방식으로 저장되고 있는데, 만약 Tuple 2가 삭제된다면 어떻게 될까?

이렇게 되면 Tuple의 삽입위치를 제대로 찾을 수 없을 것이다.
또한, 만약 Tuple이 가변길이를 가질 경우에도 문제가 된다.
위 예시는 Tuple들이 모두 정해진 한 칸만큼의 크기를 가진다고 가정하였기 때문에 Num Tuples를 이용해서 삽입을 진행할 수 있었지만, 가변길이를 가지는 경우 해당 데이터로 데이터의 추가를 수행할 수 없다.
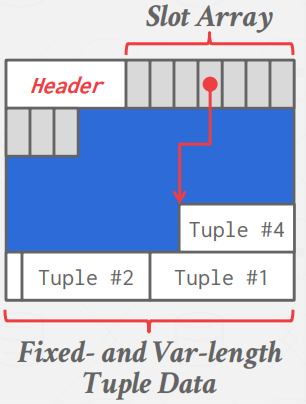
Slotted Pages
위와 같은 문제를 해결하기 위한 방식이 Slotted Pages 방식이다.

Slot Array의 entry에 해당하는 각 slot들은 tuple의 starting position과 매핑된다.
Header는 사용중인 slot의 숫자와 마지막 slot이 사용한 starting location의 offset을 저장한다.
Tuple 3이 삭제되면 다음과 같이 변화한다.
Record IDs
DBMS는 각 tuple에 대한 접근을 위해 필요한 정보를 저장해야 한다.
따라서 각 tuple은 unique한 record identifier를 배정받게 된다.
일반적으로 page_id + offset / slot 을 record id로 assign 받는다.
Tuple Layout
Tuple은 일반적으로 sequence of bytes에 해당한다.
DBMS는 이러한 바이트를 해석하여 attribute type이나 value로 변환한다.
Tuple Header
Tuple의 prefix는 header에 해당하며, tuple에 대한 meta-data를 가지고 있다.
주로 Visibility info나 NULL values 정보에 대한 Bit Map을 가지고 있다.
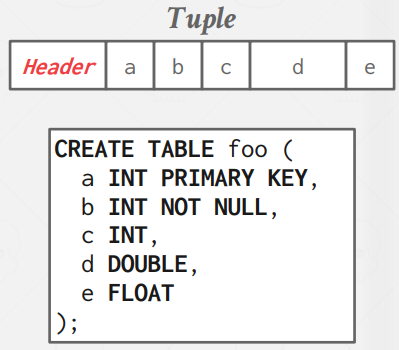
일반적으로 Attribute는 테이블 생성시 정의했던 순서대로 Tuple에 담기게 된다.
Denormalize Tuple Data
DBMS는 related tuple에 대해 denormalize를 수행하고 이를 같은 페이지에 저장할 수 있다.
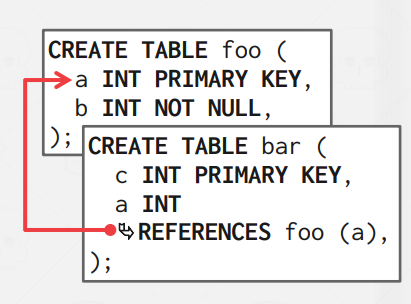
이는 pre join과 비슷한 동작으로, 일반적인 workload patterns에 대해 I/O의 양을 줄일 수 있지만,
updates에 필요한 cost가 높아지는 단점이 존재하기도 한다.
'DB' 카테고리의 다른 글
| [Database System] Hash Table (0) | 2023.10.09 |
|---|---|
| [Database System] Database Storage2 (0) | 2023.10.07 |
| [Database System] Normalization (0) | 2023.10.05 |
| [Database System] SQL과 NOSQL (0) | 2023.10.02 |
| [Database System] Modern SQL (0) | 2023.09.17 |