![[Database System] Modern SQL](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F83A12%2FbtstzwQi7JA%2FAAAAAAAAAAAAAAAAAAAAAAre6NgoBUaOR4WyPA09k5bYQ1U7i0Jf2MOic66WT0l7%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3Dk9XsYKvzl2Zt7Jd6QnyrdUrVlRM%253D)
CMU의 Intro to Database System / Fall 2022를 바탕으로 정리 한 것입니다.
Modern SQL
Relational Languages에는 DML, DDL, DCL 의 세 가지 Language가 존재하며, sets이 아닌 bags를 기반으로 작동한다.
즉, 중복되는 튜플이 존재한다는 것을 가정하고 작동되도록 구성되어있다.
앞으로 보여줄 예시에 대한 데이터베이스 구조는 아래와 같다.

Aggregates
`bags of tuples로 부터 하나의 value를 리턴하는 함수`에 해당한다.
- AVG(col) => col value의 평균 값을 리턴한다.
- MIN(col) => col value의 최소 값을 리턴한다.
- MAX(col) => col value의 최대 값을 리턴한다.
- SUM(col) => col의 value의 총 합을 리턴한다.
- COUNT(col) => col의 values들의 개수를 리턴한다.
이러한 Aggregates 함수들은 SELECT 의 구문과 주로 사용된다.

다음과 같이 여러 개의 Aggregates 함수를 엮어 사용할수도 있다.

DISTINCT
DISTINCT 키워드를 COUNT, SUM, AVG 등의 Aggregates와 함께 사용할 수 있는데, 이 경우 중복된 값을 제외하고 연산을 진행한다. 즉, Set 기반으로 작동하는 것처럼 변경할 수 있다.

GROUP BY
Aggregates 함수 사용 시 해당 column을 제외한 다른 columns의 output을 SELECT 구문에 포함시킬 경우 에러가 발생한다.

위와 같은 구문은 사용할 수 없다.
이 문제를 해결하기 위해서는 GROUP BY 키워드를 사용해야 한다.
GROUP BY 키워드를 사용하면 tuple들을 subset 들로 project한 후, 각각의 subset에 대해 aggregates가 진행된다.


aggregated value에 해당하지 않는 column들에 대해서는 만드시 GROUP BY를 적용해주어야 에러가 발생하지 않고 원하는 값을 얻을 수 있다.
Having
aggregation compuation 결과에 기반하여 결과를 필터링해주는 역할을 한다.
GROUP BY에서 WHERE 절과 유사한 역할을 한다.
아래와 같은 SELECT 문을 가정해보자

위와 같은 구문은 사용할 수 없다. 왜냐하면 WHERE 절의 경우 GROUP BY로 묶이기 전 각 레코드에 대해 검사를 수행하기 때문이다.
avg_gpa의 경우 부분집합에 대한 연산이 끝난 후 생기는 column이기 때문에 WHERE 절로 조건하는 순간에는 존재하지 않고, 따라서 에러를 발생시킨다.
이런 경우 다음과 같이 HAVING 을 사용하여 문제를 해결할 수 있다.

String Operations
Like
string을 매칭하는데 사용되는 키워드이다.
=> %의 경우 empty string을 포함하여 모든 substring에 대해 매칭된다.
=> _ 의 경우 하나의 문자에 매칭된다.

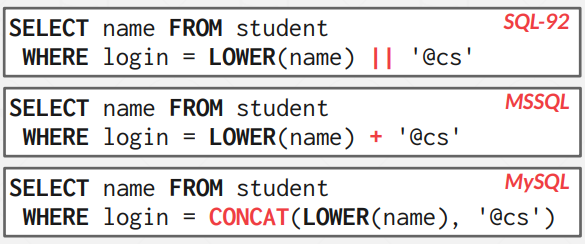
||
두개 이상의 문자열을 합치는데 사용한다.
||의 경우 SQL standard 문법이며, MSSQL와 MySQL의 경우 아래와 같이 사용한다.
ORDER BY
tuple 결과 값을 value에 따라 정렬하는 키워드이다.


위와 같이 ORDER BY 1로 정렬한 경우, 첫 번째 칼럼에 대해 정렬을 시작한다.
헷갈릴 수 있는데, 테이블의 칼럼 번호는 1부터 시작한다
당연히 0부터 인줄 알았다..
이 외에도 ASC, DESC 등의 정렬 조건을 넣어줄 수 있다.

LIMIT
연산 결과로 리턴되는 tuple의 개수를 한정할 수 있는 키워드이다.

위 예시는 조건을 만족하는 record에서 sid, name column만을 뽑아 10개의 record를 리턴한다.

OFFSET을 사용하면, 시작점으로 몇 번째 record를 지정할 지 알 수 있다.
즉 위 예시에서는 조건을 만족하는 Record가 30개 존재한다고 10번째 Record부터 20개의 Record를 리턴하게 된다.
Nested Queries
쿼리를 중첩해서 사용할 수 있다.
다만, optimize하는 과정이 매우 어렵고 비용이 많이 들기 때문에 과도하게 많이 사용하는 것은 추천하지 않는다.

Nested Query를 작성하는 논리적인 흐름은 다음과 같다.

위 그림에서 살펴볼 수 있듯이, 현재 학생 테이블에서 이름을 뽑고 싶은데,
15-445를 `cid`로 가지는 사람들의 `sid` set에서 뽑고 싶은 상황이다.

따라서 다음과 같이 Inner 쿼리를 작성해서 원하는 작업을 수행할 수 있다.
서브쿼리에 사용되는 expression들은 다음과 같다.

사용 예시들은 다음과 같다.
그럼 다음 예시를 통해 Nested Query에 대한 이해를 확인해보자

학생들이 단 한 명도 등록하지 않은 수업들을 SELECT해야한다.
어떻게 sub query를 구성해야할까?
위에서 살펴본 expression 중 `EXISTS`가 가장 먼저 떠오를 것이다.
현재 문제는 `단 한명도 등록하지 않은` 이기 때문에 `단 한명이라도 등록한`에 어울리는 EXIST를 반대로 사용하면 된다.
즉, NOT EXIST 키워드를 사용할 수 있다.

이제는 서브쿼리를 마저 완성시켜주면 된다.
enrolled table에서 cid와 courese table에서의 cid를 비교하여 SELECT를 수행하면
enrolled table의 해당 record가 존재하는지 유무를 알 수 있기 때문에 다음과 같이 구성한다.

이렇게 하면, 우선 서브쿼리에서는
enrolled table에서 cid와 course table cid를 비교하며 일치하는 모든 레코드를 반환한다.
만약 레코드가 존재하면, 해당 course에 등록한 학생이 있는 것이고
레코드가 존재하지 않으면, 해당 course에 등록한 학생이 없는 것이다.
따라서 레코드가 존재하지 않는 course의 cid에 대하여 SELECT가 수행되고, 원하는 결과를 얻을 수 있다.
'DB' 카테고리의 다른 글
| [Database System] Database Storage2 (0) | 2023.10.07 |
|---|---|
| [Database System] Database Storage (0) | 2023.10.05 |
| [Database System] Normalization (0) | 2023.10.05 |
| [Database System] SQL과 NOSQL (0) | 2023.10.02 |
| [Database System] Introduction (0) | 2023.09.08 |