![[Database System] Join Algorithm](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdqQDmB%2FbtsysoBaJRf%2FAAAAAAAAAAAAAAAAAAAAAOqrt80GbJeB9BNDiMISIF-xn2gcorvYMA-SSM9Xmi06%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DQOL7WcDJy0pGD1jGcjNw7%252FpwbUk%253D)
Join Algorithms
우리는 Relational Database에서 데이터의 중복을 방지하기 위해 정규화를 수행한다.
이후, 다시 original tuple을 복구하기 위해 사용하는 것이 join operator이다
이번 파트에서는 inner equijoin algorithm을 중심적으로 살펴볼 것이며, 사실 대부분의 다른 join 알고리즘은 이 binary inner equijoin algorithm에서 파생된 것이다.
일반적으로 우리는 join을 수행할 때 더 작은 테이블을 left table(outer table)로 설정한다.
Optimizer는 실제 join plan을 세우고 수행하는 과정에서 이를 자동적으로 수행한다.
Query Plan
쿼리가 입력되면, operators들은 tree 형태로 배치된다.
Data flow는 leave of the tree에서 root로 이동하는 방향으로 진행되며, output of root node는 쿼리의 결과값에 해당한다.
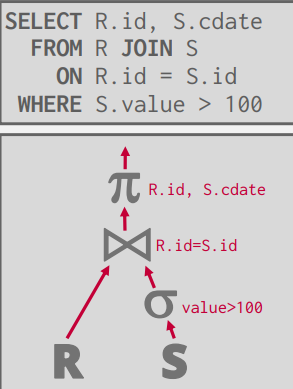
Join Operators
Join 과정에서 고려해야 하는 사항은 크게 두개이다.
1. join operator는 parent operator에게 어떤 데이터를 emit해야 하는가?
2. 어떻게 특정 join algorithm이 다른 알고리즘에 비해 효율적인지 판단할 수 있는가?
우선 1번 기준, 즉 join operator가 어떤 데이터를 emit하게 할 지에 따라
Early Materialization과 Late Materialization으로 구분할 수 있다.
Early Materialization
Early Materialization은 가장 직관적인 방법으로, join의 결과로 Data를 리턴하는 방법이다.
outer, inner tuple의 값을 복사하고 새로운 tuple으로 리턴한다.

이 방법의 장점은 join 이후의 operator들이 데이터를 얻기 위해 기존 base table로 돌아가지 않아도 된다는 것이다.
Late Materialization
Late Materialization은 parent operator에게 join 결과로 Record Ids를 리턴한다.

위와 같이, matching 되는 tuple들에 대해서 Record Id를 담은 tuple을 리턴하게 된다.
이는 column stores에 이상적인 방법인데, Late Materialization을 사용하면 쿼리에 필요하지 않은 data에 대한 copy 작업을 스킵할 수 있기 때문이다.

다음으로, 앞서 언급했던 2번 기준인, Cost Analysis Criteria를 고려했을 때 Join 방식에서의 변화에 대해 살펴보겠다.
Cost Analysis Criteria를 고려하여 Join에는 다양한 알고리즘이 존재한다. 그러나 모든 시나리오에서 최적으로 동작하는 알고리즘은 존재하지 않으며, 따라서 상황에 맞게 효율적인 알고리즘을 선택해야한다.
Join 알고리즘에는 Nested Loop Join, Sort-Merge Join, Hash Join등이 존재한다.
Nested Loop Join
Nested Loop Join은 가장 단순한 Join 알고리즘이다.
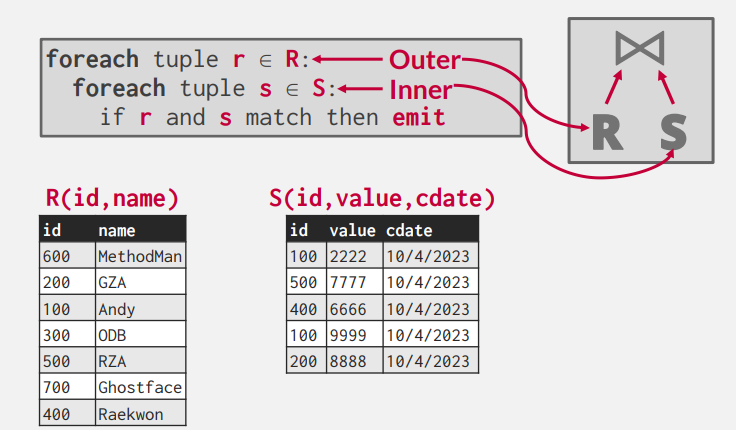
위와 같이, 각 테이블의 레코드를 모두 검사하며 match 되는 경우 emit하는 알고리즘이다.

Cost의 경우 위와 같다.
테이블에 해당하는 데이터가 총 M개의 pages에 존재하며, 총 m tuples로 이루어져 있다고 할 때,
시간 복잡도는 M + (m*N)이 된다.
여기서 시간 복잡도는 page를 읽는 Disk I/O가 매우 크기 때문에 위와 같이 산출된 것이다.
한 번 Page에 접근한 후 sequential한 Data를 읽는 속도는 Disk I/O에 비해 상대적으로 매우 작아서 무시할 수 있기 때문이다.
만약 Disk I/O를 고려하지 않고 소프트웨어적인 알고리즘으로 생각한다면 m * n 으로 간주해도 큰 무리는 없다.
이렇게 생각해도 해당 알고리즘이 매우 비효율적인 알고리즘인 것은 동일하다.
M = 1000, m = 100,000, N = 500, n = 40,000이라고 할 때, 아래와 같은 Cost가 발생한다.

예시를 살펴보면, outer table을 어떤 table로 잡는지에 따라 Cost에 꽤나 큰 영향을 주는것을 확인할 수 있다.
따라서 table의 size를 확인하는 것은 매우 중요한데, table의 size는 tuple의 수가 아니라 page의 수로 측정하는 것이 일반적이다.
Nested Loop Join의 이러한 비효율성을 극복하려면 어떻게 할까?
이전 강의에서 살펴보았던 index를 활용하면, inner table과의 matching 과정에서 발생하는 sequential scans를 하지 않을 수 있다는 점을 쉽게 떠올릴 수 있다.
이 방법을 활용한 것이 `Index Nested Loop Join`이다.

S.id를 사용하여 만든 index tree에 대해서 r_i를 넣어 검사를 진행한다.
만약 r_i와 매칭되는 s가 있는 경우에만 emit을 진행하기 때문에, m개의 tuple에 대해 상수 시간이 소모되게 된다.
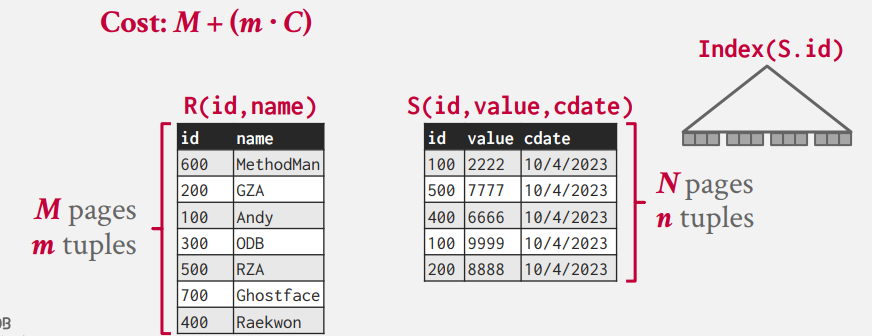
따라서 index 테이블 탐색에 걸리는 시간을 C라고 하면,
Cost는 M + (m*C)가 된다.
Sort-Merge Join
sort-merge join은 Sort와 Merge라는 2가지 phase로 구성되어있다.
1. Sort
join에 사용할 key에 대해서 양 쪽 테이블을 정렬한다.
2. Merge
두 개의 sorted table에 대해 cursor를 설정하고, matching되는 tuple을 emit한다.
알고리즘은 아래와 같다.
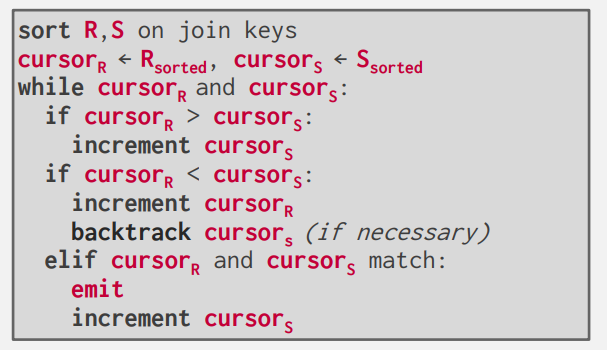
이제 구체적인 동작 과정을 살펴보자
다음과 같이 R, S테이블이 있을 때, id를 기준으로 JOIN하는 쿼리가 입력되었다고 하자.

우선 id를 기준으로 SORT가 진행된다.
이후 다음과 같이 테이블이 변경된다.

이제 cursor를 사용하여 양 측 테이블의 튜플을 서로 비교한다.

첫 커서를 통해 비교했을 때, 양 쪽 테이블의 id가 서로 같기때문에 Output Buffer에 두 튜플을 합쳐 저장한다.
이후 cursor_s를 증가시켜 비교한다.
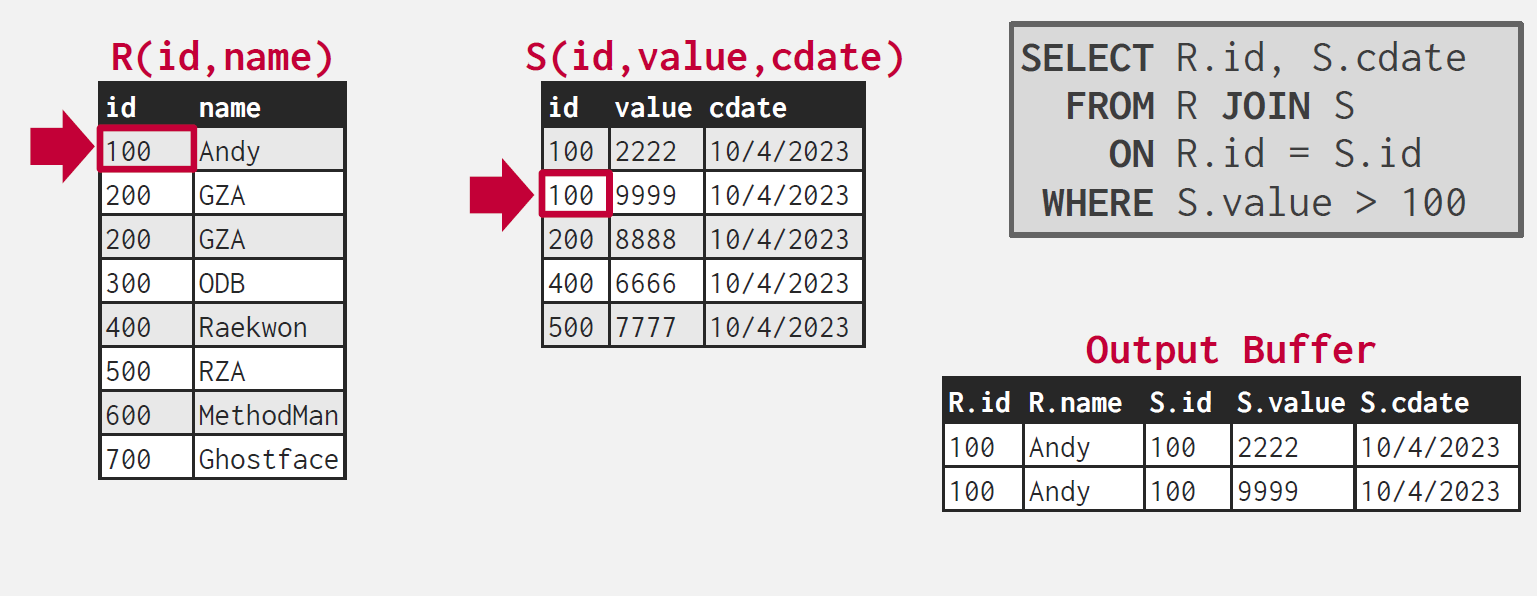
다시 id가 같으므로 저정하고, cursor_s를 증가시킨다.

S 테이블의 id가 더 크기때문에 cursor_r을 증가시킨다.

다시 id가 같으므로 저장하고 S의 커서를 증가시킨다.

이제 R의 커서 id가 더 작으므로 R의 커서를 증가시킨다.

그리고, 위와 같은 상황이 앞서 확인했던 알고리즘에서 백트래킹을 해야하는 상황에 해당한다.
R의 커서를 증가시켰음에도 불구하고, R 커서의 id가 S 커서의 id보다 작다면, S 커서를 위로 한칸 올리는 백트래킹을 진행한다.

이후 두 커서의 id가 같으므로 저장된다.
위와 같은 과정을 반복하면, 조건에 맞는 모든 tuple에 대해 join 연산을 수행할 수 있다.
이제 시간복잡도를 살펴보면, Sort-Merge Join의 시간복잡도는 다음과 같다.

Sort-Merge Join의 worst case는 join 하려는 두 테이블의 모든 tuple이 같은 value를 가지고 있는 경우로, 이 경우 Merge Cost가 M * N이 되기때문에 Total Cost는 (M * N) + (sort cost)가 된다.
Sort-Merge Join은 이미 두 테이블이 join key에 따라 정렬되어 있는 경우나, 결과값이 join key에 대해 정렬되어 있어야 하는 경우 유용하게 사용될 수 있다.
Hash Join
Hash를 이용하여 Join을 효율적으로 수행하는 방법으로, 가장 단순한 방법으로는 `Simple Hash Join`이 있다.
Simple Hash Join
다음과 같은 2 phase로 구성된다.
1. Build
outer table을 스캔하고, hash function h1을 사용하여 join 대상 속성에 대해 hash table을 생성한다.
2. Probe
inner table을 스캔하고, Build단계에서 사용했던 hash function h1을 각 tuple에 사용하여 hash table의 해당 location으로 이동하고 matching되는 tuple을 탐색한다.

Hash Table 내부에는 Key와 Value가 존재한다.
Key는 해당 쿼리가 조인하는 attributes에 해당한다.
이는 hash collision 발생시, correct matching인지 아닌지 검증하기 위한 용도로 사용한다.
Value는 DBMS마다 다른 값을 저장하는데, join의 output을 어떤 형태로 구성할지에 따라 다르게 저장된다.
즉, 앞서 살펴본 Early, Late Materialization에 따라 결정된다.
효율적인 탐색을 위해 `Probe Filter`를 사용하기도 한다.
이는 Bloom Filter의 일종으로, build 단계에서 생성된다.
이후 Probe 단계에서 직접 hash table을 확인하기 전에 Probe Filter를 먼저 검사하며, inner table에 해당하는 키가 hash table에 존재하는지 여부를 Probe Filter를 통해 확인한다.
Probe Filter에 키가 존재하는 것이 확인되면, 해시 테이블로 이동해 Join을 수행한다.
Probe Filter는 CPU cache에 fits되기 때문에, 직접 Hash Table을 검사하는 것에 비해 속도가 매우 빠르다.
만약 hash table이 저장될만한 충분한 메모리가 존재하지 않을 경우 buffer pool manager에 의해 우리가 사용해야 할 hash table이 random하게 swap out되는 경우가 발생할 수 있다.
이를 방지하기 위해 도입된 방식이 Grace Hash Join(Partitioned Hash Join)이다.
Grace Hash Join(Partitioned Hash Join)
Grace Hash Join은 다음과 같은 2가지 단계로 수행된다.
1. Partition Phase
양 쪽 테이블에서 join 속성에 대한 Hash를 수행하고 이를 partitions으로 저장한다.
2. Probe Phase
각 테이블의 일치하는 partition 간에 조인을 수행한다.
구체적인 동작 과정은 다음과 같다.
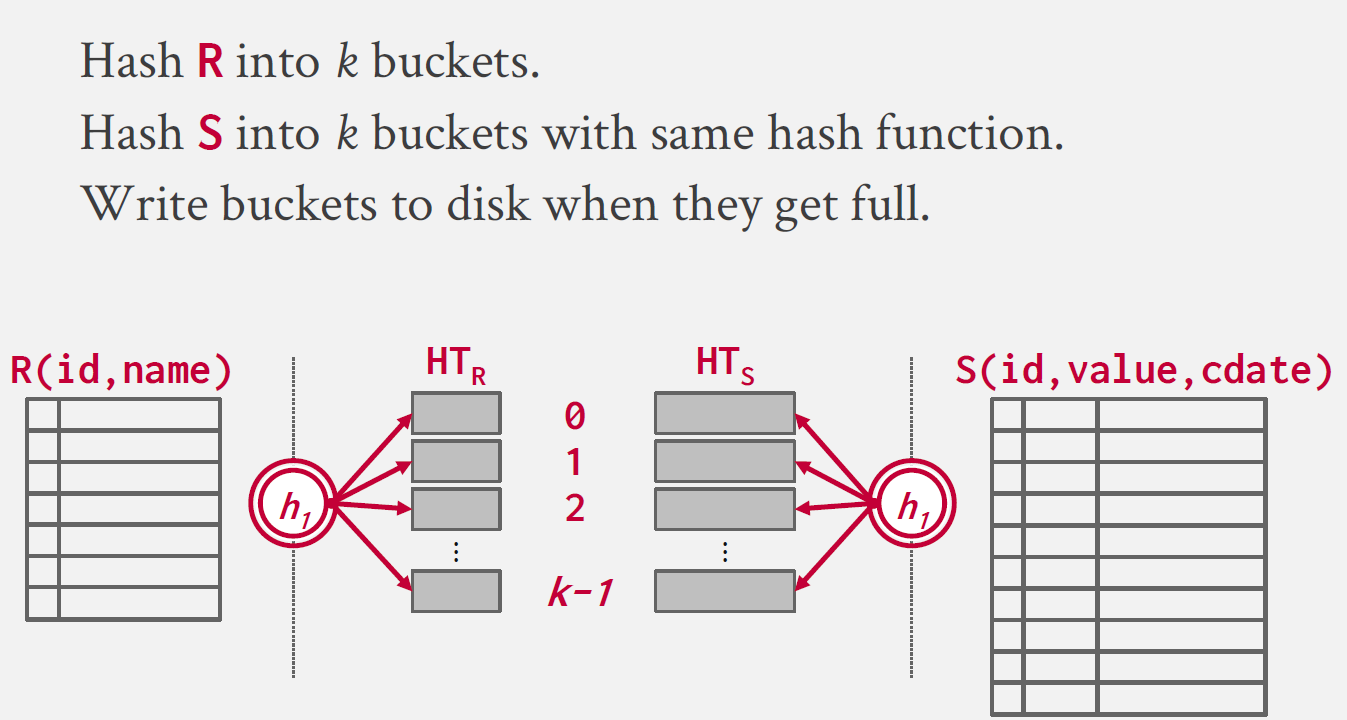
우선 각 테이블에 대해 동일한 hash 함수를 사용하여 k개의 buckets으로 partition을 수행한다.
여기서 같은 bucket에 담긴 tuple들은 같은 join key를 가진다.
따라서 같은 bucket끼리만 join 연산을 수행해주면 된다.

grace hash join의 장점은, 해시 테이블이 너무 커서 메모리에 올라가지 않는 경우를 table을 작은 partition으로 나누는 방법을 통해 방지할 수 있다는 것이다.
만약 partition도 memory에 fit하지 않는 경우, 재귀적으로 새로운 hash 함수를 사용하며 partition을 더 작게 나누는 방법으로 해결할 수 있다.

만약 recursive partitioning이 필요하지 않은 경우, Cost는 3(M+N)이 된다.
이는 Partition phase에서 양 쪽 테이블을 read하고, write하는데 2(M+N) I/O가 요구되고
Probe phase에서 양 쪽 테이블을(모든 partition에 대해) read작업이 발생하기 때문에, M+N I/O가 요구되기 때문이다.
Hybrid Hash Join
Join시에 메모리와 디스크를 효율적으로 활용하기 위한 최적화 기법 중 하나로, Join Key가 불균형하게 분포되어 있는 경우 유용하게 사용된다.
Grace Hash Join에서 메모리 크기에 맞게 Partition으로 hash table을 나누고, 각 partition간에 조인 작업을 수행하는 것을 확인하였다.
그러나 특정 hash key가 다른 것보다 훨씬 더 자주 발생하는 Skew한 상황이 발생할 수 있다.
이런 상황에 사용되는 것이 Hybrid Hash Join으로, Skew한 키에 대한 파티션을 메모리에 보관하고, 나머지 파티션은 디스크에 저장하는 방식으로 동작한다.
이렇게 하면 Skew한 조인 작업이 디스크로 spilling 되지 않고, 메모리에서 직접 처리되게 된다.
Summary
지금까지 살펴본 Hash Algorithm의 시간 복잡도를 정리하면 아래와 같다.

'DB' 카테고리의 다른 글
| [Database System] Recovery Algorithm (2) | 2023.10.26 |
|---|---|
| [Database System] Database Logging (0) | 2023.10.21 |
| [Database System] B+ Tree Index (0) | 2023.10.12 |
| [Database System] Hash Table (0) | 2023.10.09 |
| [Database System] Database Storage2 (0) | 2023.10.07 |