![[Database System] Recovery Algorithm](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb7DP9W%2Fbtsy38YV2w2%2FAAAAAAAAAAAAAAAAAAAAALfRQGd5dpBmcpkvo-e_8E_0I_jriKSBkupYg0VIDOSs%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D9KUvZuBsTuJPJgukeFB8NzwKPyw%253D)
Crash Recovery
Recovery Algorithm은 데이터베이스의 consistency, transaction atomicity, 그리고 durability를 failure 발생 시에도 보장하기 위한 방법이다.
Recovery Algorithm은 크게 두 파트로 나뉘어진다.
1. 정상 트랜잭션 처리 중에 실패로부터 복구하기 위한 조치
2. 실패가 발생한 후 데이터베이스를 consistency, transaction atomicity, 그리고 deurability를 보장하는 상태로 복구하는 조치
ARIES
Algorithm for Recovery and Isoliaton Exploiting Semantics의 준말로, IBM Research에서 개발된 알고리즘이다.
ARIES algorithm의 main idea는 다음과 같다.
1. Write-Ahead Logging
database의 변화가 disk에 쓰이기 전 까지 모든 변화는 log에 저장된다.
STEAL + NO-FORCE buffer pool policies가 사용된다.
STEAL이란 페이지가 버퍼 풀에서 내보내기가 가능하다는 것을 의미하고,
NO-FORCE란 변경 내용이 강제로 디스크에 기록되지 않는 것을 의미한다.
2. Repeating History During Redo
장애 상황에서 데이터베이스 관리 시스템을 다시 시작할 때, 이전에 수행된 작업을 다시 실행하고 데이터베이스를 장애 이전의 정확한 상태로 복원하는 것을 말한다.
3. Logging Changes During Undo
장애 발생 시 반복적인 실패를 방지하기 위해 Rollback 혹은 취소 작업을 로그에 기록한다.
WAL Records
https://simple-coding-place.tistory.com/42
[Database System] Database Logging
Failure Classification DBMS에서 발생할 수 있는 failure의 타입은 다음과 같다. Type1: Transaction Failure Type2: System Failure Type3: Storage Media Failures Transaction Failures 트랜잭션 실패에는 크게 두 가지 유형이 존재
simple-coding-place.tistory.com
위 Logging 게시물에서 WAL에 대해 다뤘었다.
AREIS 알고리즘에서 모든 log record는 globally unique한 log sequence number (LSN)을 가진다.
LSN은 데이터베이스에 대한 변경 사항의 물리적인 순서를 나타낸다.
Log Sequence Numbers
아래 표는 데이터베이스 시스템에서 사용되는 여러 로그 시퀀스 번호 및 그에 대한 정의이다.

Writing Log Records
데이터베이스 시스템에서 로그 레코드를 기록하고, 데이터 페이지를 디스크에 기록하기 전에 로그를 플러시 하는 과정에서 각 Log Sequence Number는 다음과 같은 역할을 한다.
1. pageLSN
각 페이지는 pageLSN이라고 불리는 특정 LSN값을 가지고 있다. 이 값은 해당 페이지에 대한 최신 업데이트를 가리킨다.
2. flushedLSN
데이터베이스 로그 파일에서 가장 마지막에 디스크로 플러시된 LSN을 나타낸다. 즉, 디스크에 영구적으로 저장된 로그의 끝을 가리키며, 이전에 디스크로 기록된 로그 레코드를 나타낸다.
데이터 페이지 x를 디스크에 기록하기 전에, 해당 페이지의 pageLSN은 flushedLSN보다 작거나 같아야한다.
이는 데이터 페이지에 대한 최신 업데이트가 디스크에 영구적으로 기록된 마지막 로그 레코드 이후에 발생한 변경 사항이 없어야 한다는 것을 의미한다.
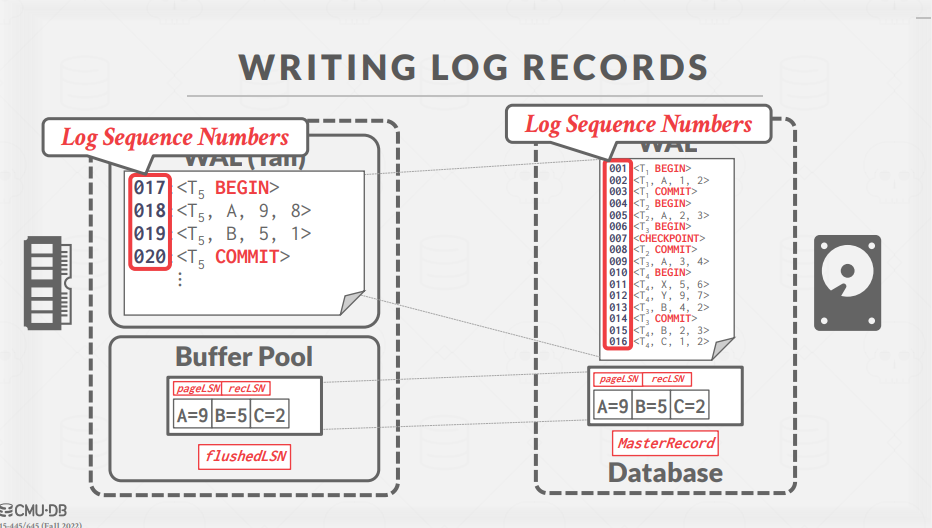

여기서 recLSN의 경우 간단하게, memory로 최초로 가져온 page의 상태를 저장한다고 생각하면된다.

flushedLSN은 disk에 있는 tail log를 참조한다.
따라서 위 예시에서 flushedLSN은 log record 16에 해당한다.

Master Record는 성공적으로 수행된 마지막 체크포인트를 참조한다.
pageLSN의 경우 transaction이 page의 record 정보를 변경할 때 마다 업데이트가 진행되며
flushedLSN의 경우 DBMS가 WAL buffer를 disk로 writes out 할 때마다 업데이트된다.
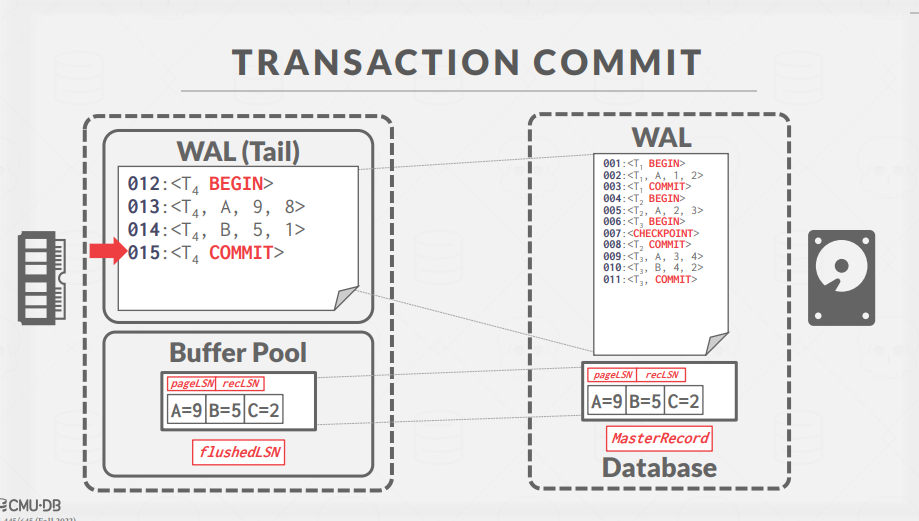
Transaction Commit
트랜잭션이 commit될 경우, DBMS는 COMMIT record를 작성하고 모든 log record가 disk로 flush 되는 것을 보장한다.
로그 플러시란 로그 레코드를 순차적이고 동기적으로 디스크에 기록하는 과정을 의미한다.
로그 레코드는 일반적으로 로그페이지에 모아져서 한꺼번에 디스크에 기록된다.
트랜잭션이 커밋에 성공하면, 특별한 TXNEND Record가 로그에 기록된다.
이 레코드는 트랜잭션이 더 이상 로그에 새로운 레코드를 생성하지 않음을 의미한다.
이는 즉시 flushed 될 필요는 없는 정보에 해당한다.

Transaction Abort
트랜잭션의 abort 과정을 관리하기 위해 로그 레코드에는 새로운 필드인 prevLSN을 필요로 한다.
이는 ARIES 회복 알고리즘의 일부로, Undo Operation을 처리하기 위해 사용된다.
prevLSN은 트랜잭션의 이전 LSN을 카리키며, 해당 트랜잭션의 로그 레코드를 연결 리스트 형태로 유지하는데 사용한다.
각 트랜잭션의 이전 로그 레코드를 추적함으로써 롤백 연산을 관리하고, 롤백 시 필요한 레코드를 빠르게 찾을 수 있다.
prevLSN을 적용한 구조는 아래와 같이 표현된다.


Abort와 TXN-END 사이에는 Abort에 의해 수행된 undo step 또한 저장되어 있다.
Compensation Log Records
보상 로그 레코드, CLR은 이전 업데이트 레코드의 작업을 취소하는 작업을 설명하는 로그 레코드에 해당한다.
CLR은 이전 업데이트 레코드의 모든 필드를 포함하며, 추가로 `undoNext pointer`를 가지고 있다.
CLR은 이전 업데이트 레코드의 역순으로 실행되며 해당 업데이트를 취소하고, 데이터베이스의 일관성을 복구하는 역할을 한다.
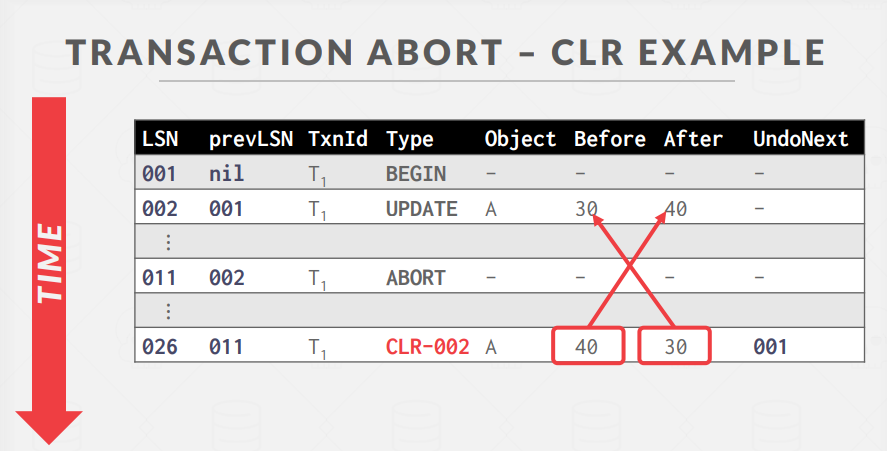
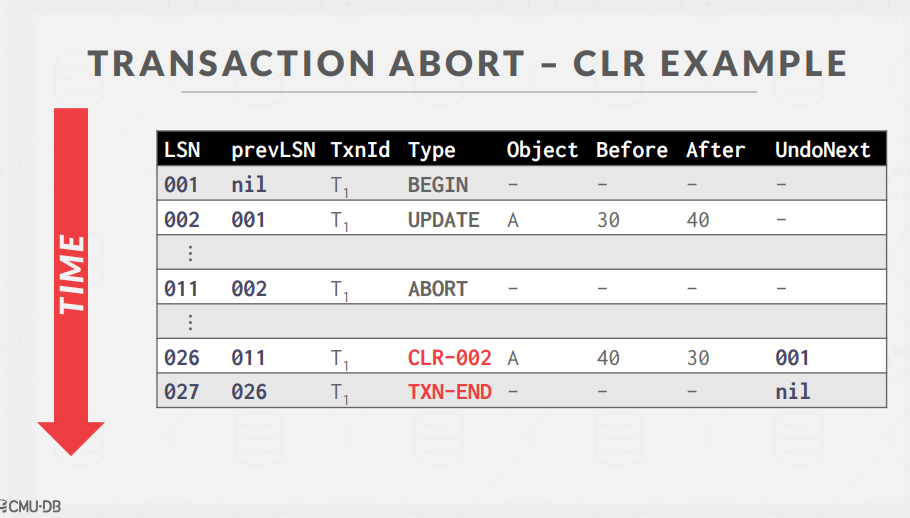
LSN 011을 확인해보면, Abort가 수행된 것을 확인할 수 있다. Abort 수행을 위해 A의 업데이트 내용을 취소해야 하고, 따라서 CLR 을 수행한다.
CLR 로그 레코드의 수행으로 인해, LSN 002에 의해 이루어진 업데이트가 취소된 것을 확인할 수 있다.
UndoNext는, 현재 작업을 수행한 이후 abort를 완료하기 위해 다음으로 수행해야 하는 작업을 가리킨다.
이후 Abort를 위한 모든 작업이 종료되었기에, 다음과 같이 TXN-END record가 기록된다.
Fuzzy Checkpointing
Non-Fuzzy Checkpoints
Non-Fuzzy Checkpoint는 DBMS에서 데이터베이스의 안전한 체크포인트를 생성하기 위한 방법 중 하나이다.
해당 작업은 데이터베이스의 안정성을 보장하기 위해 새로운 트랜잭션 활동을 중지하고, 이미 실행중인 트랜잭션이 있는 경우 해당 트랜잭션들이 종료될 때까지 대기한다.
이후, 모든 dirty page의 flush를 통해 데이터가 안정적으로 저장되도록 한다.
데이터베이스의 회복 작업을 단순히 할 수는 있으나, DB 성능에 부정적인 영향을 미칠 수 있다는 단점이 있다.
Slightly Better Checkpoints
Non-Fuzzy Checkpoints의 문제점을 해결하기 위해 일부 성능 개선을 진행한 방식이다.
실행 중인 트랜잭션의 종료를 대기하지 않고, Pause 하는 방식을 사용한다.
다만 이 방법을 실행 중인 트랜잭션을 일시 정지시켰기 때문에 체크포인트 시작 시 데이터베이스의 내부 상태를 기록해야한다.
이러한 내부 정보는 A, Dirty Page Table(DPT), Active Transcation Table(ATT)를 통해 기록한다.
Active Transaction Table
Table의 각 열은 다음과 같다.
1. tnxId
트랜잭션에 고유한 식별자인 txnId를 의미한다. 각 트랜잭션은 이 식별자를 통해 구분된다.
2. status
현재 트랜잭션의 상태 또는 모드를 나타낸다
R은 실행 중인 상태, C는 커밋 중인 상태, U는 롤백의 후보임을 나타낸다.
3. lastLSN
현재 트랜잭션에서 가장 최근에 생성된 LSN을 나타낸다.
이는 데이터베이스 상태를 복구하거나 트랜잭션 복구를 관리하는데 중요한 역할을 한다.
Dirty Page Table
버퍼 풀 내에서의 변경 내용이 디스크에 기록되지 않은 페이지를 추적하는데 사용된다.
recLSN
페이지를 더티 상태로 만든 로드 레코드를 고유하게 식별하는데 사용된다.
즉, 페이지가 언제 변경되었는지 추적하는데 사용된다.
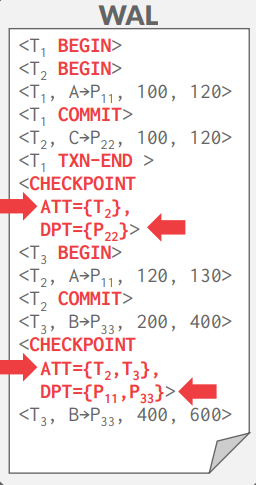
위 동작을 살펴보면, T1의 트랜잭션 종료로 인해 체크포인트가 작성되며, 해당 시점에 이미 T1의 변경사항은 disk로 flush 된 상태이다. 또한 해당 시점에 T2는 트랜잭션을 수행중인 상태이므로,
ATT에 T2가 담겨있고, DPT에 P22가 담겨 있는 것을 확인할 수 있다.
Fuzzy Checkpoints
fuzzy checkpoint는 트랜잭션 처리를 중단하지 않고 Checkpoint를 위한 로그 레코드를 기록하는 방법을 의미한다.
이를 위해 체크포인트를 추적하기 위한 새로운 log record를 사용한다.
1. CHECKPOINT-BEGIN
checkpoint의 시작 지점을 알려준다.
2. CHECKPOINT-END
ATT와 DPT 정보를 contain한다.

위 예시에서, DBMS가 P11을 첫 번째 체크포인트 시작 전에 disk로 flush 했다고 가정하자.
checkpoint start 이후에 시작된 트랜잭션인 T3는 CHECKPOINT-END record의 ATT에서 제외되어 있는 것을 확인할 수 있다.
동작이 완료되면, CHECKPOINT-BEGIN 레코드의 LSN은 MasterRecord에 적히게 된다.
ARIES - Recovery Phases
데이터베이스 시스템에서 사용되는 대표적인 회복 알고리즘인 ARIES는 로그 레코드를 사용하여 데이터베이스를 이전의 일관된 상태로 회복하는데 도움을 준다.
STEAL/NO-FORCE 정책을 채택한 WAL을 사용한다는 특징이 있다.
ARIES 알고리즘은 다음의 주요한 세 단계로 구성되어있다.
1. Analysis
이 단계에서는 WAL을 사용하여 데이트베이스 로그를 forward direction으로 분석한다. 시작점은 MasterRecord부터 이며, 이를 통해 crash가 발생한 시점의 buffer pool의 dirty pages와 active transaction을 파악할 수 있다.
2. Redo
로그 레코드를 사용하여 모든 작업을 재수행한다.
3. Undo
crash 전에 커밋되지 않은 모든 action을 되돌린다.
Analysis
마지막으로 성공적으로 수행된 체크포인트 이후부터 로그를 순방향으로 스캔한다.
스캔 도중 TXN-END 레코드를 발견하면, 해당 레코드에 기록된 트랜잭션을 ATT에서 제거한다.
다른 레코드들에 대한 처리는 다음과 같다.
우선 트랜잭션이 ATT에 없는 경우, 해당 트랜잭션을 UNDO 상태로 추가한다.
트랜잭션이 커밋된 경우, 해당 트랜잭션의 상태를 COMMIT으로 변경한다.
업데이트 로그 레코드 과정에서, page P가 DPT에 없는 경우, P를 DPT에 추가하고 페이지의 recLSN을 LSN으로 변경한다.
모든 Analysis Phase가 끝나면, ATT는 crash 발생 시 active했던 트랜잭션을 식별할 수 있게 되며, DPT를 통해 disk로 flush 되지 않은 dirty page를 식별할 수 있다.
실행 예시는 아래와 같다.

체크포인트 시작 지점을 기준으로 순방향 스캔을 시작한다.

ATT에 없는 로그 레코드를 만났으므로, ATT에 해당 레코드를 UNDO 상태로 추가한다.

또한 해당 과정은 Page Modificaiton도 진행되므로, DPT에 해당 페이지를 추가하고 RecLSN을 기록한다.

위 과정을 거치며, CHECKPOINT-END에 도달하면, 해당 ATT, DPT 정보를 기록한다.

T96 트랜잭션이 커밋되었으므로 ATT에서 상태를 COMMIT으로 변경한다.

트랜잭션 커밋이 성공적으로 종료되어 TXN-END가 기록되었으므로, ATT에서 해당 트랜잭션을 제거한다.
REDO Phase
데이터베이스 회복 과정 중의 하나로, 비정상 종료 상황에서 데이터베이스의 상태를 이전으로 복원하기 위해 필요한 작업을 수행하는 단계이다.
모든 update를 재적용하며, CLR 또한 재수행한다.
DPT에서 가장 작은 recLSN을 가진 log에서부터 forward scan을 수행한다.
수행 과정에서 Affected page이지만 DPT에 존재하지 않거나, DPT에 존재하는 Affected page이지만 record's LSN이 page의 recLSN보다 작은 경우를 제외하고 모든 update log record와 CLR을 재수행한다.
Redo를 수행하기 위해 필요한 action은 다음과 같다.
1. 모든 로그 업데이트를 reapply한다.
2. pageLSN을 log record's의 LSN으로 setting한다.
3. 추가적인 로깅이나, forced flushes를 수행하지 않는다.
Redo phase의 종료 시점에는 status COMMIT인 모든 트랜잭션에 대해 TXN-END log records를 작성하고 ATT에서 해당 트랜잭션을 제거한다.
UNDO
crash 시점에 활성화되어 있어서, commit 된 적이 없었던 트랜잭션을 모두 undo 처리한다.
이는 Analysis phase 이후에 U status인 트랜잭션을 ATT에서 찾아 수행하면 된다.
Undo 처리는 lastLSN을 사용해서, LSN 순서의 역순으로 처리된다.
모든 modification에 대해 CLR을 작성한다.
전체 동작 Example을 살펴보자.

T1에서 ABORT를 수행하여 T1의 작업 수행을 Undo하고 트랜잭션이 종료된 상태이다.

이후 트랜잭션을 순차적으로 수행하다가, CRASH가 발생했다.
이제 회복 알고리즘을 적용할 차례인 것이다.

Analysis Phase를 통해 얻은 ATT, DPT의 정보는 위와 같다.
ATT를 통해 T2, T3 모두 UNDO 작업이 필요한 상황임을 파악할 수 있다.
ATT에 적힌 lastLSN을 통해 우선적으로 reverse 해야 하는 log를 알 수 있다.
로그 레코드 번호의 역순으로 진행되므로, LSN 60 부터 Undo를 수행한다.

이후 T3에 대한 Undo를 수행한다.

T3의 경우 LSN 50에 해당하는 업데이트만 취소해주면 모든 UNDO 작업이 완료되므로, 모든 dirty page와 WAL을 디스크로 플러시하고 TXN-END 레코드를 기록한다.

여기서는 T3의 TXN-END 이후 다시 크래시가 발생한 상황을 상정한다.
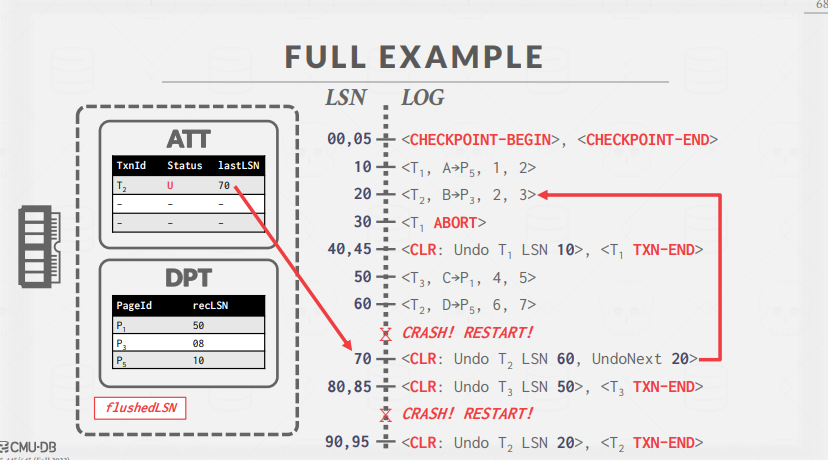
크래시 발생으로 Analysis Phase가 다시 진행된다.
T3의 경우 TXN-END 레코드가 적혀있으므로, 이번에는 ATT에 기록되지 않은 것을 확인할 수 있다.
이런식으로, 데이터베이스는 리커버리 과정에서 크래쉬가 발생하면, 크게 달라지는 과정 없이 analysis, Redo, Undo phase를 순차적으로 다시 수행한다.
'DB' 카테고리의 다른 글
| [Database System] Database Logging (0) | 2023.10.21 |
|---|---|
| [Database System] Join Algorithm (0) | 2023.10.15 |
| [Database System] B+ Tree Index (0) | 2023.10.12 |
| [Database System] Hash Table (0) | 2023.10.09 |
| [Database System] Database Storage2 (0) | 2023.10.07 |